1. 라이브러리 및 데이터 호출
#라이브러리
import tensorflow as tf
# 모델 구성 라이브러리
# Embedding 레이어: 텍스트 데이터의 임베딩을 처리. 각 단어를 고정된 크기의 벡터로 매핑.
# Bidirectional LSTM 레이어: LSTM 레이어를 양방향으로 사용하여 문맥을 이해하고 순서 정보를 고려.
# Dense 레이어: 분류를 위한 완전 연결 레이어.
# Dropout 레이어: 과적합을 방지하기 위해 랜덤으로 입력 유닛을 0으로 만듬.
from tensorflow.keras.layers import Dense, LSTM, Embedding, Dropout, Bidirectional
from tensorflow.keras.models import Sequential
#데이터 전처리 라이브러리
# Tokenizer를 사용하여 텍스트를 토큰화하고 정수 시퀀스로 변환.
# pad_sequences 함수를 사용하여 시퀀스의 길이를 맞춥니다. 모든 시퀀스를 동일한 길이로 만듬.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import tensorflow_datasets as tfds
import numpy as np
import matplotlib.pyplot as plt
#데이터 호출
dataset, info = tfds.load('imdb_reviews', with_info=True, as_supervised=True)
#데이터 저장소 확인
train_dataset, test_dataset = dataset['train'], dataset['test']
len(train_dataset), len(test_dataset)2. 단어사전 구축 + 데이터 저장 + 저장된 데이터 수열(Vector화) + padding 작업 진행
# preprocessing + padding
train_sentences = list()
train_labels = list()
test_sentences = list()
test_labels = list()
#트레이닝 셋 분리
for sent, label in train_dataset:
train_sentences.append(str(sent.numpy()))
train_labels.append(label.numpy())
#테스트 셋 분리
for sent, label in test_dataset:
test_sentences.append(str(sent.numpy()))
test_labels.append(label.numpy())
print(train_sentences[:10])
print(len(train_sentences))
print(train_labels[:10])
print(len(train_labels))
print(test_sentences[:10])
print(len(test_sentences))
print(test_labels[:10])
print(len(test_labels))#데이터셋 > 라벨 : 넘파이 형태로 전처리
train_labels = np.array(train_labels)
test_labels = np.array(test_labels)
print(train_labels.shape)
print(test_labels.shape)
#Tokenizing 작업
# (1) 단어사전 사이즈 지정
vocab_size = 10000
tokenizer = Tokenizer(num_words = vocab_size, oov_token='<OOV>')
tokenizer.fit_on_texts(train_sentences)
print(tokenizer.index_word)
# (2) Sequences 수혈로 바꾸기
train_sequences = tokenizer.texts_to_sequences(train_sentences)
test_sequences = tokenizer.texts_to_sequences(test_sentences)
print(train_sequences[0])
print(test_sequences[0])
# (3) padding 길이 맞추기
plt.hist([len(s) for s in train_sequences] + [len(s) for s in test_sequences], bins=50) #bins 간격의미
plt.show()
max_length = 150
train_padded = pad_sequences(train_sequences, maxlen=max_length, truncating="post", padding="post") #Vector화된 train_sequences에 대해 글자길이제한 및 150자가 넘으면 뒷부분을 자르기위해 truncating 사용
test_padded = pad_sequences(test_sequences, maxlen=max_length, truncating="post", padding="post") #Vector화된 test_sequences에 대해 글자길이제한 및 150자가 넘으면 뒷부분을 자르기위해 truncating 사용
print(f"padding처리된 sequence화된 트레이닝셋 {train_padded.shape}")
print(f"padding처리된 sequence화된 테스트셋 {test_padded.shape}")#수열sequence 및 padd작업 결과
print(train_padded[-1])
print(test_padded[-1])
*TMI 수열된 값(Vector화) 복원
# (4) 수열로된것을 원래의 문자로 만들기
# 함수정의
def decode_review(sequence):
return ''.join([tokenizer.index_word.get(i,"<pad>") for i in sequence]) #"<pad>" sequence로 0으로 나타난것들을 표시하기 위해
decode_review(train_padded[-1])
3. 모델 생성
# 모델 만들기 : model define
model = Sequential()
# 임베딩 디멘젼은 임베딩 벡터의 차원을 나타냄. 임베딩은 텍스트 데이터를 수치화하고 단어를 벡터 형태로 표현하는 기술임. 이러한 임베딩은 단어의 의미를 보존하면서 모델이 이해할 수 있는 형태로 변환.
# 임베딩 디멘젼을 선택하는 것은 모델의 하이퍼파라미터 중 하나입임. 일반적으로 임베딩 디멘젼이 클수록 단어의 품질이 더 좋아질 수 있지만, 모델의 복잡성이 증가하고 연산량이 늘어날 수 있음. 반대로 임베딩 디멘젼이 작을 경우 단어의 표현이 축소되어 정보 손실이 발생할 수 있음.
# 예를 들어, 위의 코드에서 임베딩 디멘젼은 64로 설정되어있음. 따라서 각 단어는 64차원의 임베딩 벡터로 표현됨.
model.add(Embedding(vocab_size + 1, 64)) #Embedding: 입력 텍스트의 각 단어를 임베딩 벡터로 매핑합니다. vocab_size + 1은 단어 집합(Vocabulary)의 크기에 1을 더한 값으로, 단어 인덱스를 임베딩 벡터로 매핑하는 데 사용됩니다. 임베딩 차원은 64로 설정. +1은 pad가 추가되었기떄문에 지정
model.add(Bidirectional(LSTM(64))) #양방향 LSTM 레이어를 생성. 이 레이어는 입력 시퀀스를 정방향과 역방향으로 모두 처리하여 시간에 따른 양쪽 방향의 문맥 정보를 모두 활용함.
model.add(Dense(64,activation="relu")) #Dense: 64개의 뉴런을 가진 완전 연결 레이어. 활성화 함수로는 ReLU(Rectified Linear Unit) 함수가 사용.
model.add(Dense(1,activation="sigmoid")) #Dense: 이진 분류를 수행하기 위해 하나의 뉴런을 가진 완전 연결 레이어. 활성화 함수로는 시그모이드(Sigmoid) 함수가 사용.
#손실함수와 최적화(확률적 경사하강법) 지정model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy'])
model.summary()
4. 모델 학습
%%time
# model.fit: TensorFlow나 Keras에서 모델을 학습시키는 함수입니다. 모델을 정의하고 컴파일한 후에 사용됩니다. 이 함수는 주어진 데이터로 모델을 학습하고 성능을 평가합니다.
# epochs=num_epochs: 이 변수는 전체 데이터 세트를 몇 번 반복해서 모델을 학습할지를 결정합니다. num_epochs는 이전에 정의된 변수로, 학습 과정을 몇 번 반복할지를 지정합니다.
# batch_size=128: 학습 데이터를 한 번에 처리하는 데 사용되는 샘플의 수를 나타냅니다. 더 큰 배치 크기는 학습 속도를 높일 수 있지만 메모리 요구 사항이 더 커질 수 있습니다.
# validation_data=(test_padded, test_labels): 이것은 모델을 학습하는 동안 검증 세트를 사용하여 모델의 성능을 평가하는 데 사용됩니다. 검증 데이터는 모델이 학습하지 않는 데이터로, 일반화 성능을 평가하는 데 중요합니다.
# verbose=1: 학습 과정 중에 로그를 출력할지를 결정합니다. 0이면 출력하지 않고, 1이면 진행 막대와 함께 출력하고, 2이면 각 epoch마다 한 줄씩 출력합니다.
num_epochs = 30
history = model.fit(train_padded, train_labels, epochs=num_epochs, batch_size=128,
validation_data=(test_padded, test_labels), verbose=1)
5. 모델 시각화
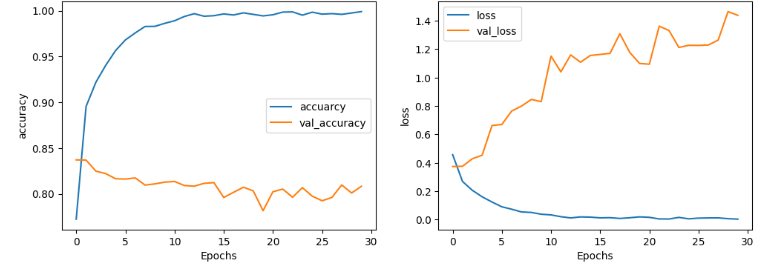
6. 모델 테스트
# 테스트
# (1) 테스트 데이터
sample_text = ['The movie was terrible. I would not recommend the movie']
# sample_text = ['The movei was fantastic. I would recommend the movie']
# sample_text = ['The animation and graphics were out of this world']
# (2) 테스트 데이터 수혈로 전처리
sample_seq = tokenizer.texts_to_sequences(sample_text)
# (3) 테스트 데이터 패딩작업
sample_padded = pad_sequences(sample_seq, maxlen=max_length, padding='post', truncating='post')
# (4) 예측 : model.predict / 0에 가까우면 부정, 1에 가까우면 긍정
model.predict(sample_padded)
'Python > NLP&LLM' 카테고리의 다른 글
| Tokenizer 심화 (0) | 2024.05.03 |
|---|---|
| RNN(Recurrent Neural Network) (0) | 2024.05.02 |
| Word Embedding과 Word2Vec (0) | 2024.05.02 |
| 문장 Vector 작업 (0) | 2024.05.01 |
| 자연어 처리(Natural Language Processing) 및 발전단계 (0) | 2024.04.30 |



