□ One-Hot-Encoding 문제점 : 단어를 단순히 index번호에 따라 one-hot-encoding으로 vectorize하므로 단어간의 유사성 파악 못함. 즉 우리는 단어간의 유사성을 파악할 수 있어야함.
https://dandora-90.tistory.com/330
문장 Vector 작업
□ Vector 화 작업 : 텍스트 문장을 숫자 벡터로 변환하는 과정을 말함. 자연어 처리에서 텍스트 데이터를 다룰 때, 컴퓨터가 이해할 수 있는 형태로 변환해야하며 이를 위해 텍스트를 숫자로 표현
dandora-90.tistory.com
□ 단어간의 유사성 파악을 위해 Word Embedding 활용(현대 딥러닝 모델의 근간이됨)
○ 단어/문장간 관련도계산
○ 의미적/문법적 정보 함축(vetorize만으로는 의미를 부여한 것이 아님)
○ 전이학습가능
○ 숫자화된 단어아의 나열로 부터 sentiment 추출
○ 연관성있는 단어들을 군집화하여 multi-dimension 공간에 vector로 표시
○ 단어나 문장을 vectort space로 끼워 넣음 = embedding
- ex)호감, 비호감 두가지 label에 따라 관련 단어들을 두개의 category로 군집화
- negative = boring, bad / positive = funny, good, interesting
○ One-Hot-Vector에 Projection Matrix(Embedding Layer)를 곱해 새로운 Vector 생성함. 즉, 행렬곱 진행
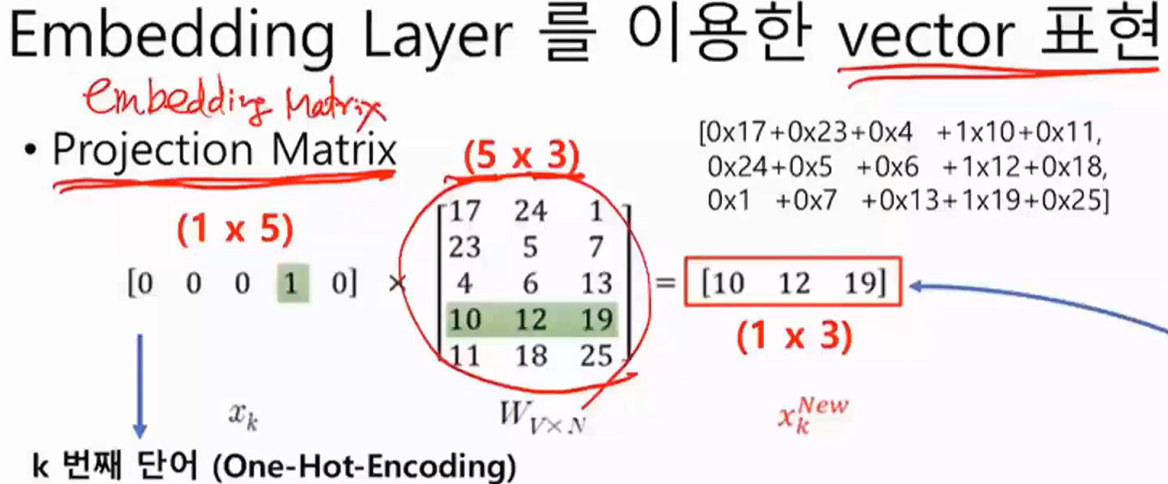

○ Projection Matrix의 k번째 row가 k 번째 단어에 대응하는 weight임
○ Word Embedding은 단어를 고정된 크기의 실수 벡터로 매핑하는 기술을 일반적으로 의미함. 즉, 단어를 밀집된(dense) 공간에 임베딩하여 의미적 관계와 구조를 보존하는 표현으로 변환하는 것을 말함
○ Word Embedding은 다양한 자연어 처리 작업에서 효과적으로 사용되며, Word2Vec은 그 중에서도 널리 사용되는 방법 중 하나임
□ Word2Vec
○ Word2Vec은 Word Embedding의 한 유형
○ Word2Vec은 Word Embedding의 구현 중 하나로, 주변 단어와의 관계를 활용하여 단어를 벡터로 표현함
○ One-Hidden Layer 의 shallow network → 최초의 neural embedding model 매우 큰 Corpus(10~100억 단어)에서 비지도학습 진행

○ skip-gram : 중심단어로 주변단어 예측하는 과정에서 단어를 벡터로 임베딩
○ CBOW : 주변단어로 중신단어를 예측하는 과정에서 단어를 벡터로 임베딩
○ 임베딩 단어의 내적(inner product)이 코사인 유사도가 되도록 함
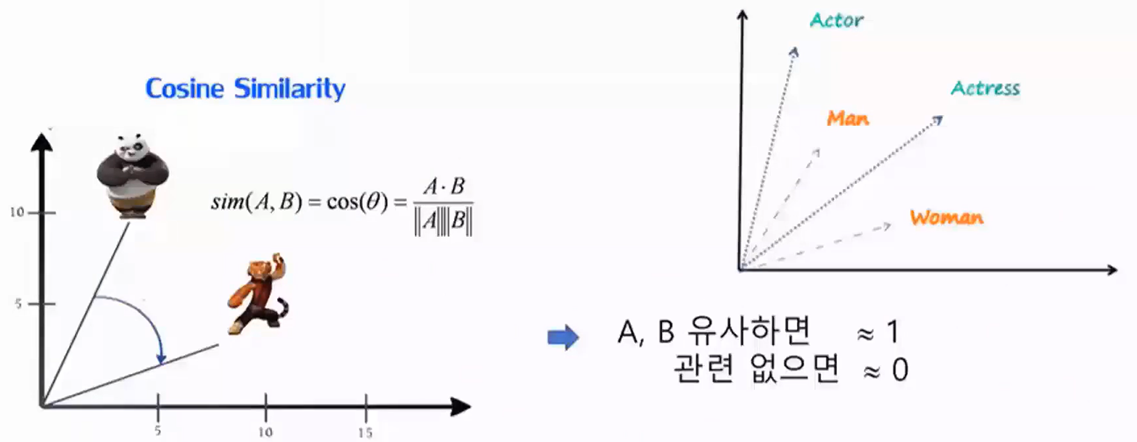
○ Word2Vec은 단어 간의 의미적 유사성을 캡처하기 위해 텍스트 데이터를 학습하여 각 단어를 밀집된 공간에 매핑함
○ Word Embedding은 Word2Vec 이외에도 다양한 방법으로 구현될 수 있음. ex) GloVe(Global Vectors for Word Representation), FastText 등
○ Word2Vec은 Word Embedding의 한 종류로서, 단어를 밀집된 벡터로 효율적으로 표현할 수 있는 방법 중 하나임
'Python > NLP&LLM' 카테고리의 다른 글
| 영화리뷰 : 감정분석 (1) | 2024.05.03 |
|---|---|
| RNN(Recurrent Neural Network) (0) | 2024.05.02 |
| 문장 Vector 작업 (0) | 2024.05.01 |
| 자연어 처리(Natural Language Processing) 및 발전단계 (0) | 2024.04.30 |
| 요약 : LLM관련 용어 (0) | 2024.04.30 |



