□ Vector 화 작업 : 텍스트 문장을 숫자 벡터로 변환하는 과정을 말함. 자연어 처리에서 텍스트 데이터를 다룰 때, 컴퓨터가 이해할 수 있는 형태로 변환해야하며 이를 위해 텍스트를 숫자로 표현하는 여러 가지 방법이 있음.
○ BOW (Bag of Words)
- CountVectorizer는 Python의 scikit-learn 라이브러리에 포함된 클래스로, 텍스트 데이터의 토큰화(tokenization)와 단어 빈도 수를 기반으로 하는 피처 벡터(feature vector)를 생성하는 데 사용.
from sklearn.feature_extraction.text import CountVectorizer
- 이 클래스는 자연어 처리(Natural Language Processing, NLP)와 텍스트 마이닝에서 널리 사용
- 모든 문장을 토큰화하고 각 문장의 토큰이 몇 번 등장하는지 Count함.
- 단어 빈도 계산(Word Frequency Counting): 각 단어가 문서 내에서 나타나는 빈도를 계산
- 각 token을 Feature화함.
- 단어들간의 순서를 유지할 수 없는 한계가 있어, 이를 위해 n-grams 기법으로 일부 해결할 수 있지만 feature 개수가 기하급수적으로 증가한다는 문제가 발생해 TF-IDF 기법이 생김.
ex) 1-gram : token 한개 / 2-gram : token 두개
- 피처 벡터 생성(Feature Vector Creation): 각 문서를 단어의 빈도를 나타내는 벡터로 변환합니다. 이 벡터는 머신러닝 알고리즘에 입력으로 사용
from sklearn.feature_extraction.text import CountVectorizer
#corps : 말뭉치
sentences = ["I love my dog",
"I love my cat",
"I love my dog and love my cat",
"You love my dog",
"Do you think my dog is amazing?"]
count_vectorizer = CountVectorizer() #객체생성
features = count_vectorizer.fit_transform(sentences)#말뭉치를 입력으로 학습진행
features
print(features.shape) #문장개수, 단어 개수
print(f"문장개수 : {features.shape[0]}")
print(f"단어개수 : {features.shape[1]-1}")
#벡터 배열로 변환
vectorized_sentences = features.toarray()
vectorized_sentences
feature_names = count_vectorizer.get_feature_names_out() #생성된 백터 단어키워드 조회 : get_feature_names_out()
feature_names
#단어별 등장회수 데이터프레임으로 확인
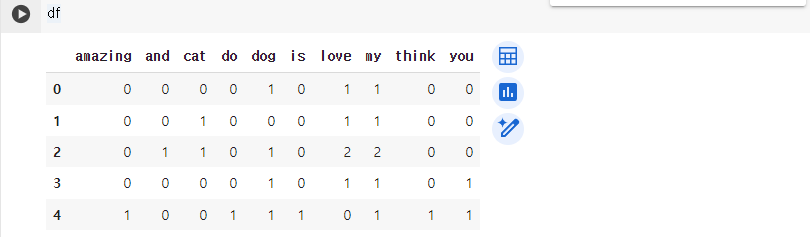
df = pd.DataFrame(vectorized_sentences, columns=feature_names)
○ TF-IDF (Term Frequency - Inverse Document Frequency)
- Scikit-learn의 TfdfVectorizer method 사용
from sklearn.feature_extraction.text import TfidfVectorizer
- TF(단어빈도) : 특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값. 이 값이 높을 수록 특정 문서에서 중요하다고 간주
- DF(문서빈도) : 단어 자체가 전체문서집단내에서 사용되는 빈도. DF가 높으면 그 단어가 흔하게 등장하는 것을 의미
- TF-IDF = TF * DF
- low TF-IDF(전체 문서에서 공통으로 사용되는 단어의미), high TF-IDF(모든 문서가 아닌, 특정 문서에서 자주 사용되는 단어의미)
- TF-IDF는 단어의 빈도와 그 단어가 드물게 나타나는 문서에 더 높은 가중치를 부여하는 방식으로 작동.
#TF-IDF(Term Frequency Inserve Document Frequency)
#TF-IDF는 단어의 빈도와 그 단어가 드믈게 나타나는 문서에 더 높은 가중치를 부여하는 방식으로 작동
from sklearn.feature_extraction.text import TfidfVectorizer
#corps : 말뭉치
sentences = ["I love my dog",
"I love my cat",
"I love my dog and love my cat",
"You love my dog",
"Do you think my dog is amazing?"]
tfidf_vectorizer = TfidfVectorizer() #tfdf 객체 생성
tfidf_sentences = tfidf_vectorizer.fit_transform(sentences)
tfidf_sentences
tfidf_sentences.shape
tfidf_vect_features = tfidf_sentences.toarray()
tfidf_vect_features #정규화된 배열로나옴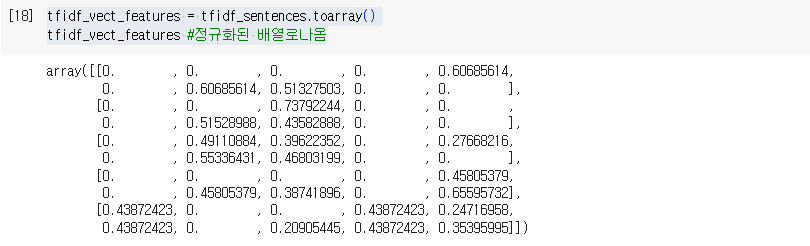
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
tfidf_feature_names
df = pd.DataFrame(tfidf_vect_features, columns = tfidf_feature_names)
df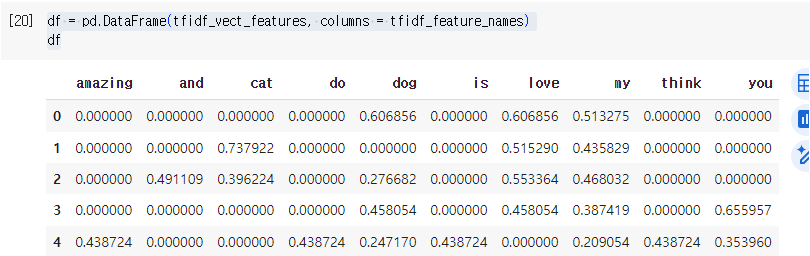
○ keras word encoding - Keras word API 사용
- 데이터 토큰화 / 단어사전 생성 및 적재(파라미터 조정) - 단어사전의 문장 Sequence화 - 데이터 길이 맞춤 - 원-핫 인코딩 진행
- 단어사전에 없는 신규 데이터 발생시 이를 처리하기위해 <OOF> out of feature 로 표시되도록 파라미터 조정
※ BOW, TF-IDF는 예전방식이고 요즘은 DeepLearning을 활용함.
#keras word encoding
#라이브러리
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer #토큰화 라이브러리
from tensorflow.keras.preprocessing.sequence import pad_sequences #문장길이 맞춤 라이브러리
from tensorflow.keras.utils import to_categorical #모든 입력을 one-hot-encoding vector화#Tockenize
#단어사전 생성
sentences = ["I love my dog",
"I love my cat",
"I love my dog and love my cat",
"You love my dog",
"Do you think my dog is amazing?"]
tokenizer = Tokenizer(num_words = 100, oov_token="<OOV>") #num_words 사전단어개수, oov_token 신규단어에 대해서 oov 지정
tokenizer.fit_on_texts(sentences) #데이터 학습 및 사전에 추가
print(tokenizer.word_index) # .word_index
print(tokenizer.index_word) # .index_word
#Padding
#토큰사전에서 부여된 인덱스 번호로 데이터 변환 .texts_to_sequences
sequences = tokenizer.texts_to_sequences(sentences)
sequences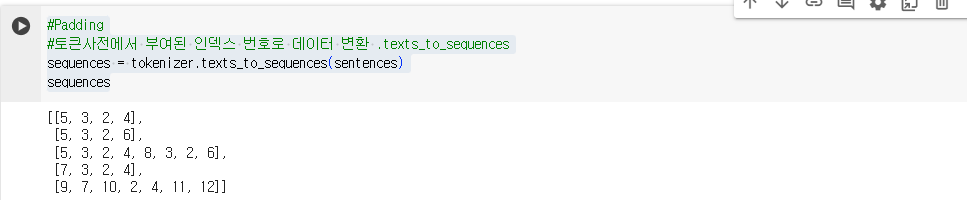
#길이를 맞춤
padded = pad_sequences(sequences)
padded
# sequenced sentence를 word sentence로 환원
tokenizer.index_word
#시퀀스 값 별 단어를 문장으로 표시
for sequence in sequences:
sent = list()
for idx in sequence:
sent.append(tokenizer.index_word[idx])
print(" ".join(sent)) #join을 활용하여 리스트의 값을 묶음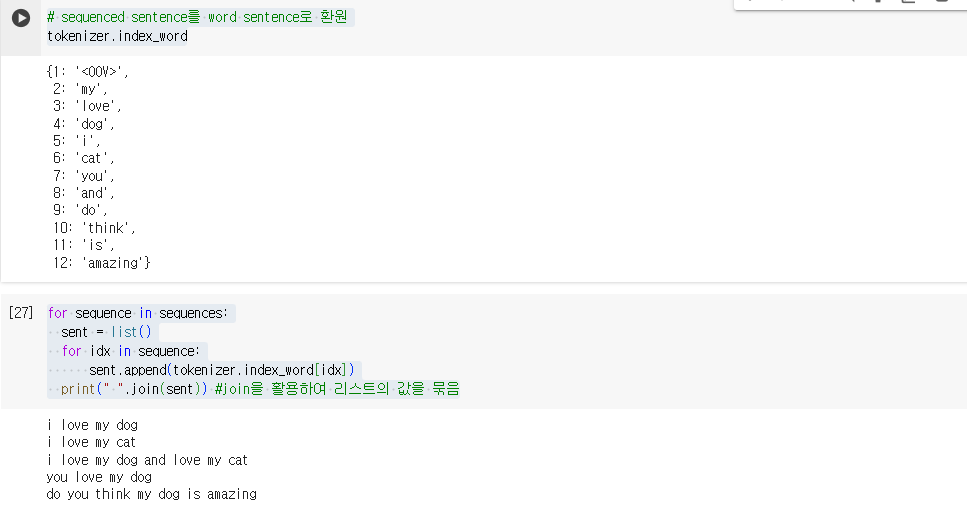
#One-Hot-Encoding
to_categorical(padded)
'Python > NLP&LLM' 카테고리의 다른 글
| RNN(Recurrent Neural Network) (0) | 2024.05.02 |
|---|---|
| Word Embedding과 Word2Vec (0) | 2024.05.02 |
| 자연어 처리(Natural Language Processing) 및 발전단계 (0) | 2024.04.30 |
| 요약 : LLM관련 용어 (0) | 2024.04.30 |
| LLM 주요용어 : Temprature 온도 (1) | 2024.04.28 |



