1. 언어 모델에서 다음 토큰의 확률 예측
2. 언어 모델링(language Modelibg)에서 다음 토큰의 예측은 다어 집합(Vocabulary)에 존재하는 단어들에 대한 Softmax Regression 값이 됨
3. 온도는 Softmax Regression의 각 토큰이 샘플링 시에 뽑힐 확률을 뾰족하게 만들어 주거나 평평하게 만들어줌
(1) 온도(Temperature) 값이 작을 경우 : 확률값이 높은 토큰의 예측 확률이 증폭. 가장 크럴듯한 토큰이 뽑힐 확률이 높아짐.
(2) 온도(Temperature) 값이 높을 경우 : 모든 토큰의 확률 값이 편평해짐. 더욱 다양성 있는 텍스틑가 생성될 확률이 높아짐.

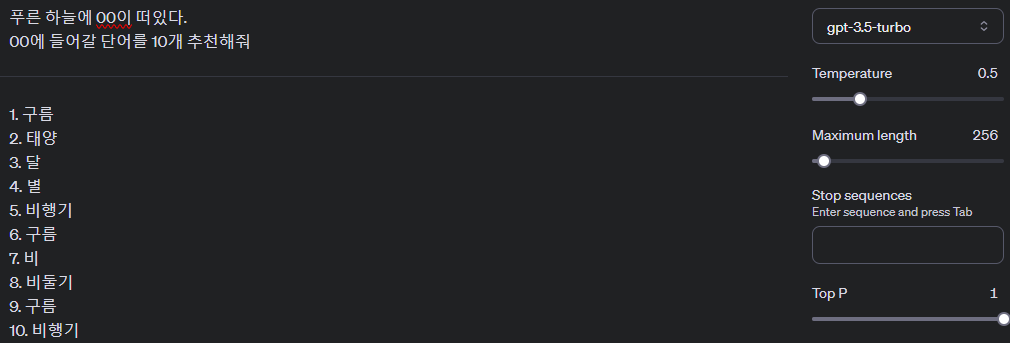

* 온도 수치를 1로 올릴수록 다양하고 중복되지 않는 키워드가 추출되는 것을 확인 할 수 있음.

'Python > NLP&LLM' 카테고리의 다른 글
| 자연어 처리(Natural Language Processing) 및 발전단계 (0) | 2024.04.30 |
|---|---|
| 요약 : LLM관련 용어 (0) | 2024.04.30 |
| LLM 주요용어 : 창발능력(Emergent Abilities) (0) | 2024.04.28 |
| LLM 주요용어 : In-context learning (0) | 2024.04.28 |
| LLM 주요용어 : 토큰(Token) (1) | 2024.04.28 |



