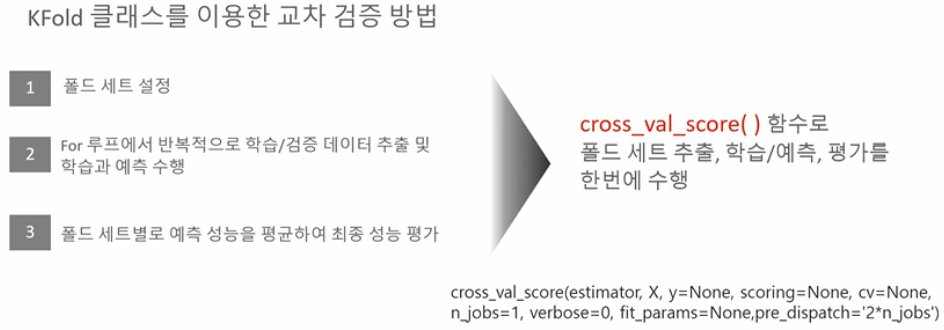
□ Cross_val_score()
○ 폴드세트설정 + For문활용 트레이닝/검증 데이터 학습 + 에측평균 성능산출작업을 한번에 작업함
○ 파라미터
- estimator : 모델
- x : feature 데이터
- y : 타겟(라벨) 데이터
- scoring : 평가함수 ex)accuracy, recall 등
- cv : 폴드시행 세트 수
#cross_val_score()
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
import numpy as np
iris_data = load_iris() #데이터 저장
#데이터 분리
data = iris_data.data
label = iris_data.target
#모델객체생성
dt_clf = DecisionTreeClassifier(random_state=156)
#학습+측정 : 교차검증 및 성능지표 정확도
#└ 정확도로 함수지정, 폴드세트 3개 지정
#└ 분류모델일 경우 cross_val_score는 자동으로 straified fold 적용, 단, 회귀모델일 경우 불가
scores = cross_val_score(dt_clf, data, label, scoring="accuracy",cv=3)
print(f"교차 검증별 정확도 : {np.round(scores,4)}")
print(f"평균 검증 정확도 : {np.round(np.mean(scores),4)}")
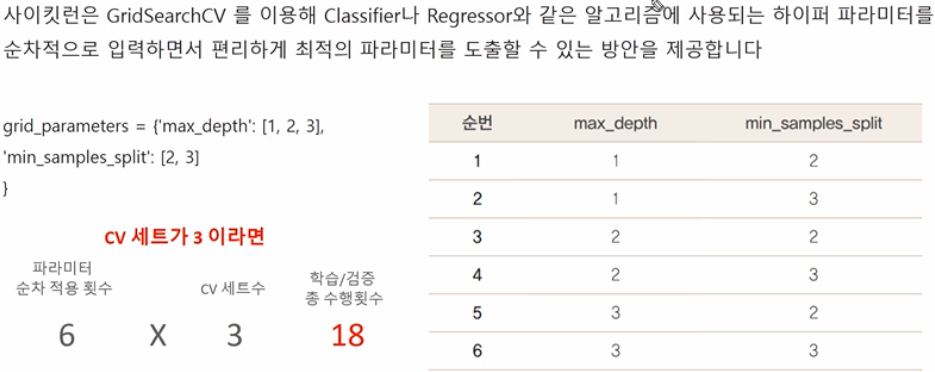
□ GridSearchCV
○ 교차검증과 최적 하이퍼파라미터 튜닝을 한번에 진행해줌
○ 알고리즘 모델에 대한 속성, 즉 파라미터들을 튜닝해줌
#GridSearch CV
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
#데이터 로딩 후 학습 데이터와 테스트 데이터 분리
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.4, random_state=121)
#모델객체생성
dtree = DecisionTreeClassifier()
#모델에 대한 파라미터 딕셔너리형태로 저장
parameters = {"max_depth":[1,2,3], "min_samples_split":[2,3]}
#parama_frid의 하이퍼 파라미터들을 3개의 train, test, set fold로 나누어 테스트 수행설정
#refit=True가 default임. True 면 가장 좋은 파라미터로 설정 후 재학습 시킴
grid_dtree = GridSearchCV(dtree, param_grid = parameters, cv=3, refit=True, return_train_score=True)
#학습 및 평가
grid_dtree.fit(X_train, y_train)
#greidsearch 결과는 cv_results_라는 딕셔너리로 저장됨 이를 데이터프레임으로 저장
scores_df = pd.DataFrame(grid_dtree.cv_results_)
print(scores_df)
scores_df[["params", "mean_test_score", "rank_test_score", "split0_test_score", "split1_test_score", "split2_test_score"]]
print(f"최적의 파라미터 : {grid_dtree.best_params_}")
print(f"최고 정확도 점수 : {grid_dtree.best_score_}")
# refit = True로 설정된 GridSearch 객체가 fit() 수행시 학습이 완료된 Estimator를 내표하고 있으므로 predict()를 통해 예측가능
pred = grid_dtree.predict(X_test)
print(f"테스트 데이터 세트 정확도 : {accuracy_score(y_test, pred)}")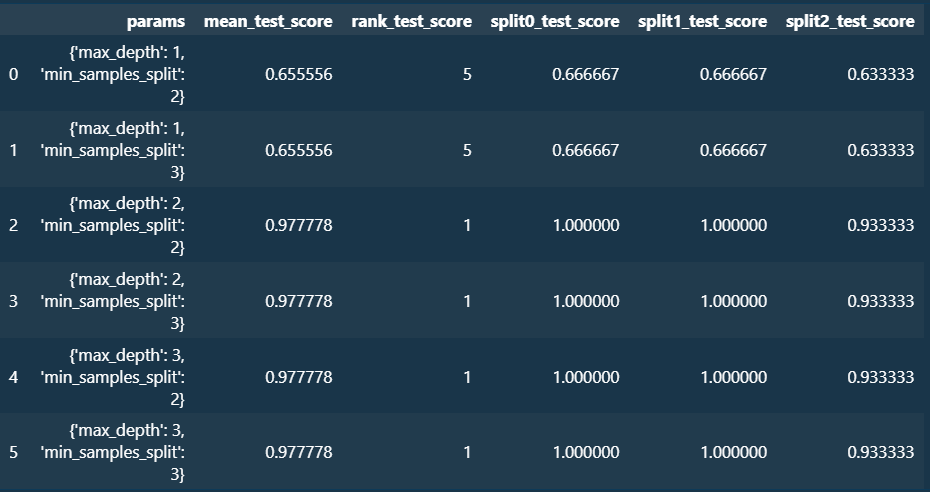

○ 사용자가 지정한 모델과 모델별 속성에 대한 파라미터 튜닝과 동시에 자체 트레이닝/검증하여 파악된 최적의 파라미터 모델 즉, estimator 를 GridSearchCh 에 저장함.
# GridSearchCV의 refit으로 이미 학습된 estimator 반환
estimator = grid_dtree.best_estimator_
# GridSearchCV의 best_estimator_는 최적 하이퍼 파라미터로 학습됨
y_pred = estimator.predict(X_test)
print(f"테스트 데이터 세트 정확도 : {accuracy_score(y_test, y_pred)}")
'Python > 머신러닝+딥러닝 Ⅱ' 카테고리의 다른 글
| 피처 스케일링(스탠다드 스케일러, 민맥스 스케일러) (1) | 2024.04.06 |
|---|---|
| 데이터 인코딩(레이블 인코딩, 원-핫 인코딩) (0) | 2024.04.06 |
| 교차검증 Ⅰ (1) | 2024.03.26 |
| 사이킷런(scikit-learn)과 지도학습 모델, 데이터셋 구축 (0) | 2024.03.26 |



