□ 사이킷런(scikit-learn)
○ 파이썬 기반의 다른 머신러닝 패키지도 사이킷런 스타일의 API를 지향할 정도로 쉽소 파이썬 스러운(단순) API를 제공
○ 머신러닝을 위한 다양한 알고리즘과 개발을 위한 편리한 프레임워크와 API 제공
○ 오랜 기간 실전환경에서 검증되어있으며 매우 많은 환경에서 사용되는 라이브러리
○ 주로 NUMPY와 SCIPY 기반위에 구축된라이브러리임
○ 사이킷런 버전확인
#사이킷런 버전확인
import sklearn
print(sklearn.__version__)
□ 지도학습 모델
| 분류 : Classifier | 회귀/예측 : Regressor |
| DecisionTreeCassifier | LinearRegression |
| RandomForestClassifier | Ridge |
| GradientBoostingClassifier | Lasso |
| GaussianNB | RandomForestRegressor |
| SVC | GradientBoostingRegressor |
○ 분류는 대표적인 지도학습 방법의 하나임.
○ 지도학습은 학습을 위한 다양한 피처와 분류 결정값인 레이블 데이터로 모델을 학습 후 별도의 테스트 데이터 세트에서 미지의 레이블을 예측함.
○ 즉 지도학습은 명확한 정답이 주어진 데이터를 먼저 학습 후 미지의 정답을 예측하는 방식임.
○ 이때 학습을 위해 주어진 데이터 세트를 학습 데이터세트, 머신러닝 모델의 예측 성능을 평가하기 위해 별도로 주어진 데이터 세트를 테스트 데이터 세트로 지칭.
○ 데이터세트분리(학습/테스트 데이터 분리) → 모델학습(ML알고리즘 적용) → 예측수행 → 평가(예측된 결과와 테스트 데이터의 실제값을 비교해 성능평가)
□ 트레이닝, 테스트 셋 분리
○ 트레이닝/테스트 셋 분리전 속성 셋과 타겟셋으로 분리
- 피쳐,속성 : 데이터 세트의 일반 속성임. 머신러닝은 2차원 이상의 다차원 데이터에서도 많이 사용되므로 타겟값을 제외한 나머지 속성을 모두 피처로 지칭.
- 타겟(값),결정(값),레이블,클래스 : 타겟값 또는 결정값은 지도학습시 데이터의 학습을 위해 주어지는 정답 데이터. 지도 학습 중 분류의 경우에는 이 결정값을 레이블 또는 클래스로 지칭.
#라이브러리
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score #정확도
import pandas as pd
import numpy as np
iris = load_iris() #아리스 데이터 실행
print(f"iris 타입 : {type(iris)}")
iris_data = iris.data #아이리스 데이터 변수저장
iris_label = iris.target #타겟명 지정
print(f"타겟값 : {iris_label}")
print(f"타겟명 : {iris.target_names}")
#데이터 셋 구축
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
iris_df["label"] = iris.target #신규컬럼생성
iris_df.head()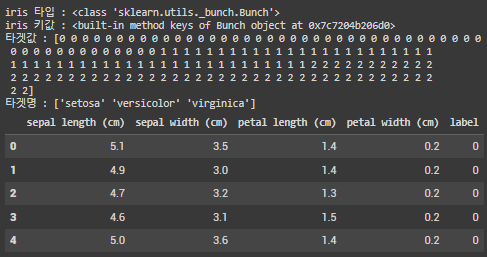
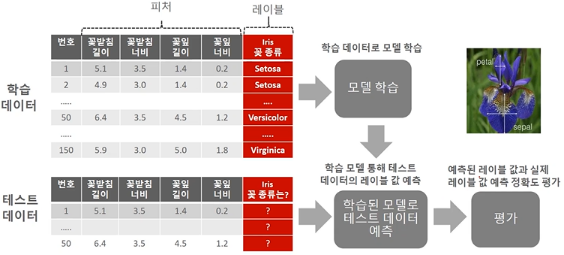
○ 트레이닝/테스트 셋 분리
- 학습데이터세트
▶ 머신러닝 알고리즘 학습을 위해사용.
▶ 지도학습의 경우 데이터 속성들과 결정값 모두드를 가지고 있어야함.
▶ 학습 데이터를 기반으로 머신러닝 알고리즘이 데이터 속성과 결정값의 패턴을 인지해야함.
- 테스트데이터세트
▶ 테스트 데이터 세트에서 학습된 머신러닝 알고리즘을 테스트.
▶ 테스트 데이터는 속성 데이터만 머신러닝 알고리즘에 제공하며, 머신러닝 알고리즘은 제공된 데이터를 기반으로 결정값을 예측.
▶ 테스트 데이터는 학습 데이터와 별도의 데이터세트로 제공되어야함.
#데이터 분리
#학습용 속성, 테스트 속성,학습용 클래스, 테스트 클래스 = train_test_split(속성데이터, 클래스데이터, 변수~)
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=11)
#모델 생성 및 분류
dt_clf = DecisionTreeClassifier(random_state=11) #모델 생성
dt_clf.fit(X_train, y_train)#학습 → fit(학습용 속성, 학습용 타겟)
pred = dt_clf.predict(X_test)#예측 → 예측/분류시 답을 넣지않고 속성데이터만 넣는다
print(f"예측값 : {pred}")
print(f"타겟값 : {y_test}")
#예측 정확도 평가 : accuracy_score(테스트 클래스, 예측변수)
print(f"정확도 : {np.round(accuracy_score(y_test, pred),2)}")
'Python > 머신러닝+딥러닝 Ⅱ' 카테고리의 다른 글
| 피처 스케일링(스탠다드 스케일러, 민맥스 스케일러) (1) | 2024.04.06 |
|---|---|
| 데이터 인코딩(레이블 인코딩, 원-핫 인코딩) (0) | 2024.04.06 |
| 교차검증 Ⅱ (1) | 2024.03.26 |
| 교차검증 Ⅰ (1) | 2024.03.26 |



