□ 학습 데이터를 다시 분할하여 학습 데이터와 학습된 모델의 성능을 일차 평가하는 검데이터로 나눔.
□ 수능을 보기전 수많은 모의고사를 치룬다고 생각하면됨.

□ K-Fold 교차검중과 Stratified K-Fold가 있는데 Stratified K-Fold를 많이 사용하는 편임.
○ 일반 K-Fold
○ Stratified K-Fold
- 불균형한 분포도를 가진 레이블(결정 클래스) 데이터 집합을 위한 K-Fold 방식
- 학습데이터와 검증 데이터 세트가 가지는 레이블 분포도가 유사하도록 검증 데이터 추출
□ 예제
○ 일반 K-Fold
#라이브러리
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris #사이킷런 내장데이터
import numpy as np
iris = load_iris() #데이터 저장
features = iris.data #데이터 속성 저장
print(f"데이터 속성형태\n\n{features.shape}")
label = iris.target #데이터 타겟 저장#모델생성
dt_clf = DecisionTreeClassifier(random_state=156)
#-kfold 인자 n_splits = k개수
kflod = KFold(n_splits=5)
#-정확도 리스트
cv_accuracy = list() #k폴드 정확도 점수의 평균산출을 위해 지정
n_iter = 0
for train_index, test_index in kflod.split(features): #kFold 객체의 split() 호출시 폴드별 학습용, 검증용 테스트의 로우 인덱스를 array형태로 반환
# print(len(train_index))
# print(train_index)
# print(len(test_index))
# print(test_index)
# └테스트 120 검증 30 총 5세트 호출
#kfold.split()으로 반환된 인덱스를 이용하여 학습용, 검증용 테스트 데이터를 추출
X_train, X_test = features[train_index], features[test_index] #학습용
y_train, y_test = label[train_index], label[test_index] #테스트용
#학습 및 예측
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
n_iter +=1
#반복할때마다 정확도 측정
accuracy = np.round(accuracy_score(y_test, pred),4)
train_size = X_train.shape[0]
test_size = X_test.shape[0]
print(f"{n_iter}번째 교차검증\t정확도 : {accuracy}\t학습데이터크기 : {train_size}\t검증데이터 크기 : {test_size}")
#정확도 점수 리스트에 추가
cv_accuracy.append(accuracy)
print(f"k폴드 최종 정확도 : {np.mean(cv_accuracy)}")
○ Stratified K-Fold
- K-Fold 한계
import pandas as pd
iris = load_iris()
iris_df = pd.DataFrame(data = iris.data, columns = iris.feature_names) #iris 속성들 필드로 저장 후 데이터프레임화
iris_df["label"] = iris.target #생성한 데이터 프레임에 신규 필드 추가
print(f'''□ 데이터\n{iris_df.head()}''')
print("\n")
print(f'''□ 타겟값 및 개수\n{iris_df["label"].value_counts()}''')#kfold
kfold = KFold(n_splits=3)
#kfold.split(x)는 폴드 세트를 3번 반복할때마다 달라지는 학습/테스트용 데이터 로우 인덱스 반환
n_iter = 0
for train_index, test_index in kfold.split(iris_df):
n_iter += 1
label_train = iris_df["label"].iloc[train_index] #교차검증 트레이닝 라벨
label_test = iris_df["label"].iloc[test_index] #교차검증 테스트 라벨
print(f"교차검증 : {n_iter}")
print(f"학습 레이블(타겟) 데이터분포\n{label_train.value_counts()}")
print(f"검증 레이블(타겟) 데이터분포\n{label_train.value_counts()}")- Stratified fold : K Fold와 다르게 Stratified fold는 매개변수를 속성값과 라벨값을 함께 넣어줘야함.
#Stratified fold
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=3)
#kfold.split(x)는 폴드 세트를 3번 반복할때마다 달라지는 학습/테스트용 데이터 로우 인덱스 반환
n_iter = 0
#Stratifiedfold의 split()호출시 반드시 레이블 데이터 셋도 추가입력필요
for train_index, test_index in skf.split(iris_df, iris_df["label"]): #k폴드와 다르게 인수로 x에서 y값까지 받도록 지정
n_iter += 1
label_train = iris_df["label"].iloc[train_index] #교차검증 트레이닝 라벨
label_test = iris_df["label"].iloc[test_index] #교차검증 테스트 라벨
print(f"교차검증 : {n_iter}")
print(f"학습 레이블(타겟) 데이터분포\n{label_train.value_counts()}")
print(f"검증 레이블(타겟) 데이터분포\n{label_train.value_counts()}")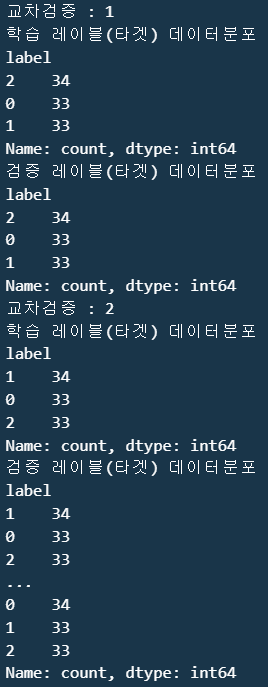
- 정리하면 Stratified fold는 K fold의 한계인 샘플링(타겟데이터) 편향을 해결하도록 타겟 데이터를 균등하게 Fold 수만큼 배분함. (아래 코드는 Stratified Fold 최종 정리코드임)
#최종
iris = load_iris() #데이터 저장
features = iris.data #데이터 속성 저장
label = iris.target #데이터 타겟 저장
dt_clf = DecisionTreeClassifier(random_state=156)
skfold = StratifiedKFold(n_splits=3)
n_iter = 0
cv_accuracy = list()
#Stratifiedfold의 split()호출시 반드시 레이블 데이터 셋도 추가입력필요
for train_index, test_index in skfold.split(features, label):
#split()으로 반환된 인덱스로 학습용, 검증용 테스트 데이터 추출
#X 속성, y 타겟
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
#학습 및 예측
dt_clf.fit(X_train, y_train) #트레이닝 셋으로 학습
pred = dt_clf.predict(X_test)
#반복시마다 정확도 측정
n_iter += 1
train_size = X_train.shape[0]
test_size = X_test.shape[0]
accuracy = np.round(accuracy_score(y_test, pred)) #바로 위코드에서 테스트용 x값을 예측했으므로 y_test와 비교를 통한 정확도 산출
cv_accuracy.append(accuracy)
print(f"{n_iter}번째 교차검증\t정확도 : {accuracy}\t학습데이터 크기 : {train_size}\t타겟데이터 크기 : {test_size}")
'Python > 머신러닝+딥러닝 Ⅱ' 카테고리의 다른 글
| 피처 스케일링(스탠다드 스케일러, 민맥스 스케일러) (1) | 2024.04.06 |
|---|---|
| 데이터 인코딩(레이블 인코딩, 원-핫 인코딩) (0) | 2024.04.06 |
| 교차검증 Ⅱ (1) | 2024.03.26 |
| 사이킷런(scikit-learn)과 지도학습 모델, 데이터셋 구축 (0) | 2024.03.26 |



