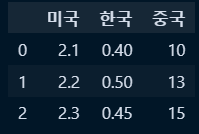
○ 인덱스 유 데이터프레임 생성: pd.DataFrame({키:벨류})
df1 = pd.DataFrame(
{
'미국' : [2.1,2.2,2.3],
'한국' : [0.4,0.5,0.45],
'중국' : [10,13,15]
}
)
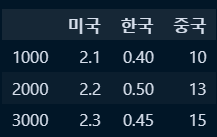
○ 인덱스 무 데이터프레임 생성 : pd.DataFrame({키:벨류}, index = [인덱스값])
df2 = pd.DataFrame(
{
'미국' : [2.1,2.2,2.3],
'한국' : [0.4,0.5,0.45],
'중국' : [10,13,15]
},
index = [1000,2000,3000]
)
○ 인덱스 조회 : 변수명.index
df2.index
○ 인덱스 변경 : 변수명.index[변경값]
df2.index=[3000,4000,5000]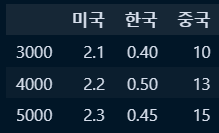
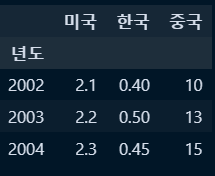
○ 신규 컬럼추가 및 해당 컬럼 인덱스로 설정 :컬럼추가 및 해당 컬럼 인덱스 지정
#컬럼생성
df2['년도'] = [2002,2003,2004]
#생성된 컬럼을 인덱스로 지정
new_df2 = df2.set_index('년도')
○ 인덱스 초기화(인덱스 명이 없다면 그냥 reset_index()라고 입력)
new_df2 = new_df2.reset_index('year')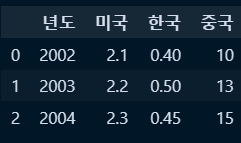
○ 특정행가져오기 : loc, iloc
- loc : 인덱스 명칭 또는 컬럼명칭 지정하여 조회
#위코드에서 new_df2.set_index('년도') 로 인덱스 재지정후 아래코드 진행
print(new_df2.loc[2002]) #인덱스명이 2002인것 행 추출
print(new_df2.loc[2003]) #인덱스명이 2003인것 행 추출
print(new_df2.loc[2004]) #인덱스명이 2004인것 행 추출
print(new_df2.loc[2002:2003]) #인덱스가 2002~2003인 행 추출
print(new_df2.loc[:,'미국']) #가로행 전체, 미국열 선택
print(new_df2.loc[:,['한국','중국']]) #가로행 전체, 한국&중국열 선택
print(new_df2.loc[:,'한국']) #가로행 전체, 한국열 선택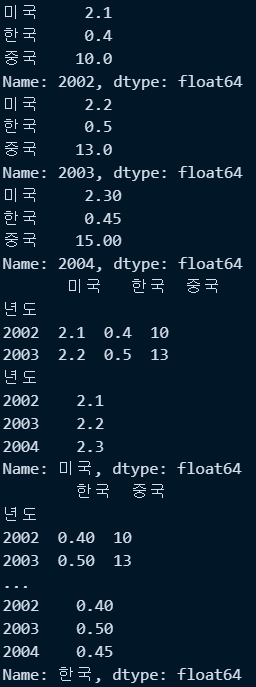
- iloc : 인덱스 번호 또는 컬럼위치번호 지정하여 조회
print(new_df2.iloc[0]) #0번째 행 추출(반환형태는 시리즈임)
print(new_df2.iloc[1]) #1번째 행 추출(반환형태는 시리즈임)
print(new_df2.iloc[2]) #2번째 행 추출(반환형태는 시리즈임)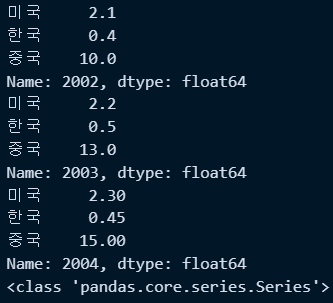
○ 신규 데이터 호출(저장경로가긴 데이터 불러오기)
#저장경로만 변수에 별도저장
path = 'C:/python/PANDAS_LECTURE/PANDASPLOTLY_FUNCODING_2024/00_Material(Uploaded)/COVID-19-master/csse_covid_19_data/csse_covid_19_daily_reports/'
#pd.read_csv와 저장경로 변수+데이터명을 활용하여 데이터 확인
doc =pd.read_csv(path+'01-22-2020.csv',encoding='utf-8-sig')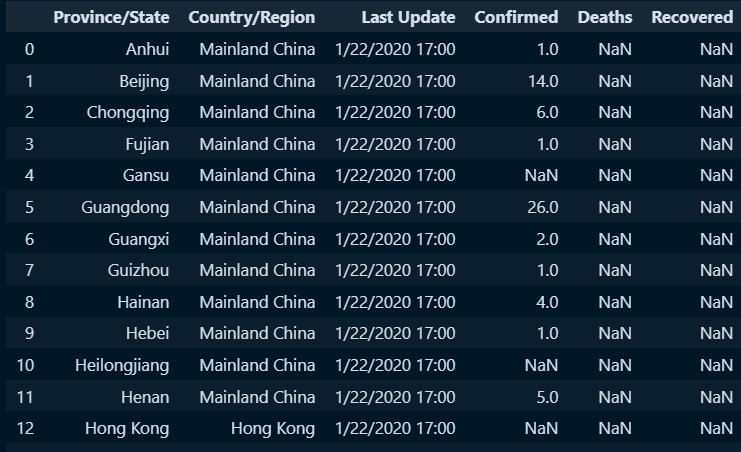
○ 불러온 데이터에서 특정 컬럼만 지정하여 시리즈로 저장
con_series = doc['Country/Region'] #특정필드 저장
print(con_series)
print(type(con_series))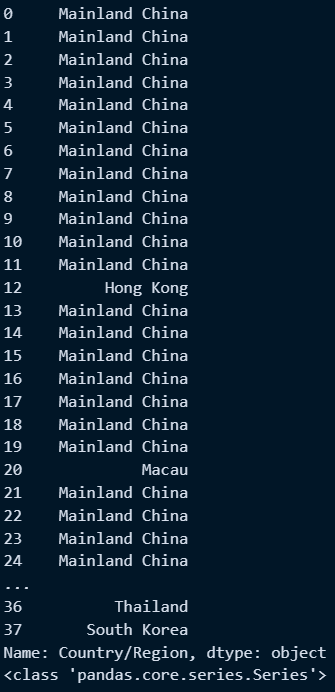
○ 결측값 확인
- .count() : 결측값을 제외하고 합산한 값
- .size : 결측값 포함하고 합산한 개수
print(con_series.size, con_series.count())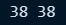
○ 고유값과 고유값 개수 구하기
- 변수명.unique()
- len(변수명.unique())
print(con_series.unique(),len(con_series.unique()))
○ 데이터별 중복개수 확인 : .value_counts()
con_series.value_counts()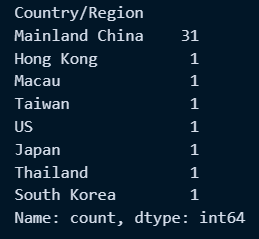
○ 복수컬럼추출 및 셋 저장
- 단일컬럼 : 변수명[컬럼1]
- 복수컬럼 : 변수명[[컬럼1,컬럼2,컬럼3]] *복수컬럼일시 []안에 리스트 지정
countries = doc[['Country/Region','Deaths','Recovered']]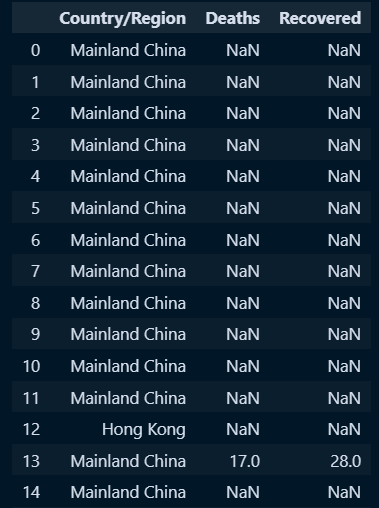
○ 특정조건에 맞는 row 검색
- 조건설정 : 변수명[컬럼명] == 값 → True, False 반환
- 조건에맞는 값 추출 : 변수명[조건] → 변수명[변수명[컬럼명] ==값]
#조건
doc['Country/Region'] =='US'
#조건에맞는것만 추출
doc[doc['Country/Region'] =='US']
○ 결측값 개수 확인
- isnull() : True, False 반환
- sum() : 통상 isnull()과 sum()함께 사용 *True는 1로 sum으로 결측값 개수 확인 가능
#isnull() : 없는 데이터가 있는지 true false 반환
doc.isnull()
#sum() 없는 데이터가 있는 행의 개수. 통상 isnull(), sum()으로 사용
doc.isnull().sum()
○ 결측값 행 삭제
- dropna() : 일반적으로 dropna를 사용하면, 예를 들때, 필드가 5개인 데이터프레임을 가정하고 각 필드의 모든 값이 NaN인 행을 모두 삭제함
doc.dropna()
- dropna(subset=필드명) : 지정한 열에서 결측치가 있는 행을 삭제하도록 지시. 이때 dropna 메서드는 지정한 열에만 영향을 미치며, 다른 열의 결측치는 변경되지 않음
doc.dropna(subset=['Confirmed'])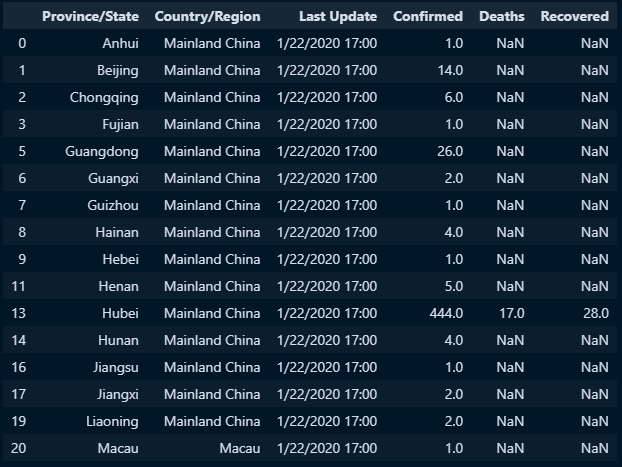
○ 결측값 특정 값으로 대체 : .fiina(채울값)
#필드별 채울값 : 딕셔너리형태로 지정
nan_data = {'Deaths':0, 'Recovered':0}
#fillna로 특정열의 결측값 채움
fillna_doc2 = doc.fillna(nan_data)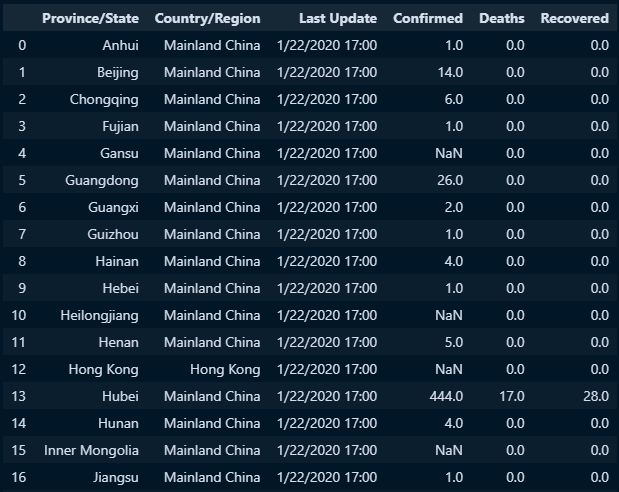
○ 집계 : groupby : sql의 groupby와 같으며 이때 지정한 필드는 인덱스로 바뀜
- groupby('필드명').집계함수
doc.groupby('Country_Region').sum()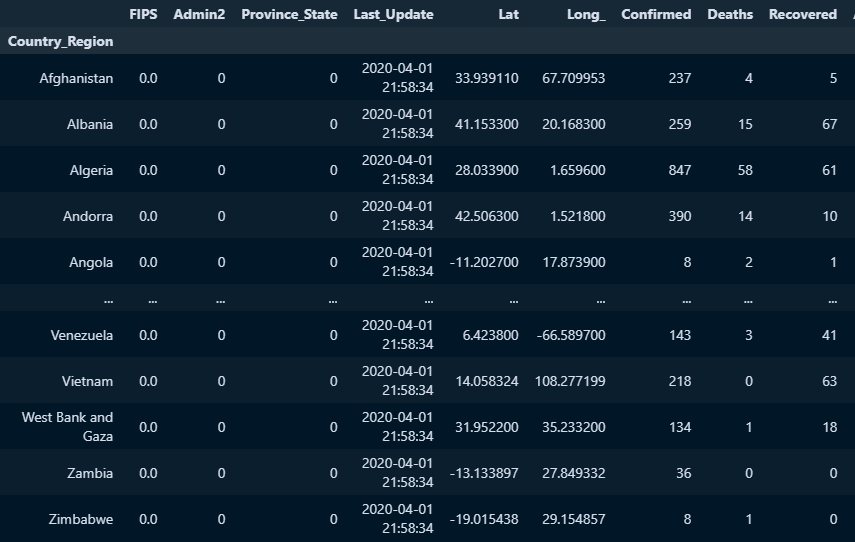
○ 데이터 프레임 합치기 : merge, concat
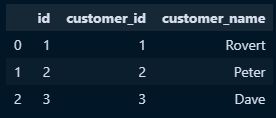
- 데이터프레임 생성
a = pd.DataFrame({
'id':[1,2,3],
'customer_id':[1,2,3],
'customer_name':['Rovert','Peter','Dave']
})
b = pd.DataFrame({
'id':[1,2,4],
'order_id':[100,200,300],
'order_date':['2021-01-21','2021-02-03','2020-10-01']
})
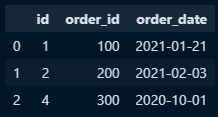
- merge
ab_merge = pd.merge(a,b)#두 데이터프레임간 동일한 이름을 가진 ㅂ칼럼을 기준으로 두데이터프레임 합침
ab_merge = pd.merge(a,b, on ='id')#두 데이터프레임간 동일한 이름을 가진 ㅂ칼럼을 기준으로 두데이터프레임 합침
#결합방법
ab_merge = pd.merge(a,b, on ='id', how ='inner')#두 데이터프레임간 동일한 이름을 가진 칼럼을 기준으로 두데이터프레임 inner 합침
ab_merge = pd.merge(a,b, on ='id',how ='outer')#두 데이터프레임간 동일한 이름을 가진 칼럼을 기준으로 두데이터프레임 outer 합침
ab_merge = pd.merge(a,b, on ='id',how ='left')#두 데이터프레임간 동일한 이름을 가진 칼럼을 기준으로 두데이터프레임 left 합침
ab_merge = pd.merge(a,b, on ='id',how ='right')#두 데이터프레임간 동일한 이름을 가진 칼럼을 기준으로 두데이터프레임 right 합침
#인덱스를 활용하여 머지
a_in = a.set_index('id') #인덱스 지정
b_in = b.set_index('id') #인덱스 지정
ab_in =pd.merge(a_in,b_in, left_index=True, right_index=True)
ab_in =pd.merge(a_in,b_in, left_index=True, right_index=True, how='outer')
ab_in =pd.merge(a_in,b_in, left_index=True, right_index=True, how='left')
ab_in =pd.merge(a_in,b_in, left_index=True, right_index=True, how='right')
- concat
#concat : 데이터 프레임 붙임
ab_heng=pd.concat([a,b], axis=0) #디폴트 행방향
print(ab_heng)
ab_yeol=pd.concat([a,b], axis=1) #열방향
print(ab_yeol)
'Python > Pandas & numpy' 카테고리의 다른 글
| Numpy Intro (1) | 2024.03.06 |
|---|---|
| Datetime & pd.to_datetime (1) | 2024.02.16 |
| 판다스 : 데이터 핸들링 예제 (0) | 2024.02.09 |
| 판다스 : groupby, 멀티인덱스 활용 조회 (0) | 2024.02.08 |
| 판다스 : 데이터 필드 형변환 (0) | 2024.02.08 |



