□ 라이브러리 및 데이터 불러오기
#라이브러리 불러오기
import numpy as np
import seaborn as sns
#데이터 불러오기
titanic = sns.load_dataset('titanic')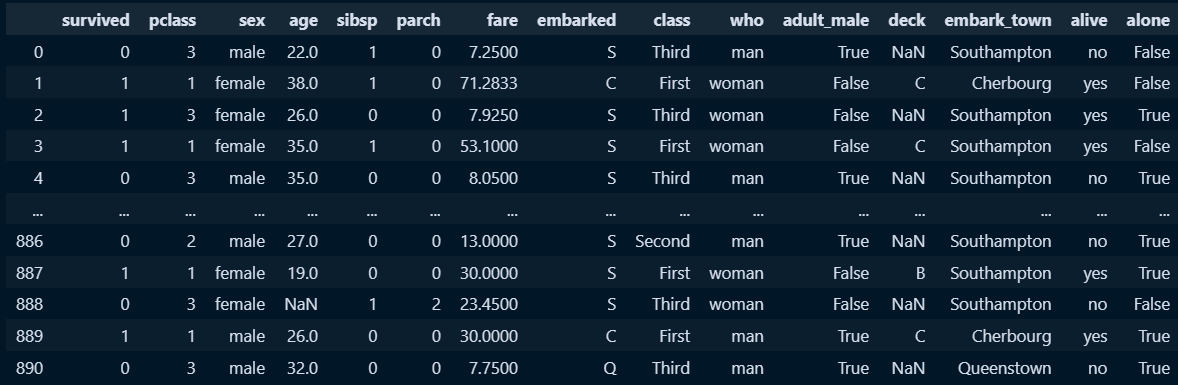
□ 지정한 필드로 데이터셋 생성
#1. 지정한 필드로 데이터셋 생성
new_titanic = titanic[['age','sex','class','fare','survived']]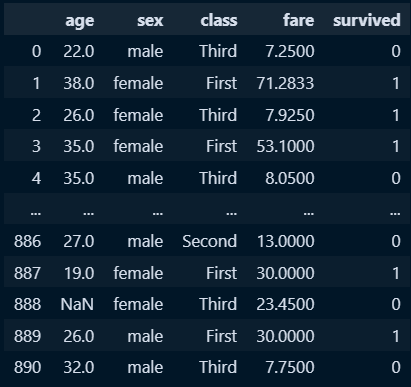
□ 특정열 복수 지정 후 그룹바이
→ 아래 코드와 같이 groupby만 진행한다면 데이터는 데이터프레임 또는 시리즈가 아닌 단순한 객체로써만 존재함
#2. class와 sex필드로 그룹바이
group_titanic = new_titanic.groupby(['class','sex'])
print(type(group_titanic))
□ 그룹바이 한 상태에서 집계함수적용
→ 그룹바이한 객체에 집계함수를 사용하면 데이터프레임이 반환되며, 그룹바이지정시 선택한 필드들은 인덱스로 전환
→ 이때 두개열이상으로 구성된 인덱스를 멀티 인덱스라고함
#3. 그룹바이한것을 바탕으로 모든열의 평균값 구하기
mean_titanic = group_titanic.mean()
□ class가 First인 데이터만 조회
→ 인덱스 Class > First에 해당하는 값이 데이터 프레임으로 산출
#4. 인덱스 class 중 first인것 추출
first_titanic = mean_titanic.loc['First']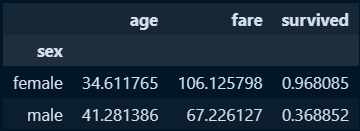
□ class가 First이고 sex가 female인 데이터만 조회
→ 기본적으로 인덱스 키는 튜플형임
→ 코드작성에따라 데이터프레임 또는 시리즈로 조회가능
#4. 인덱스 class 중 first인것 추출
a = mean_titanic.loc['First','female'] #시리즈 반환
b = mean_titanic.loc[('First','female')] #시리즈 반환
c = mean_titanic.loc[[('First','female')]] #데이터프레임 반환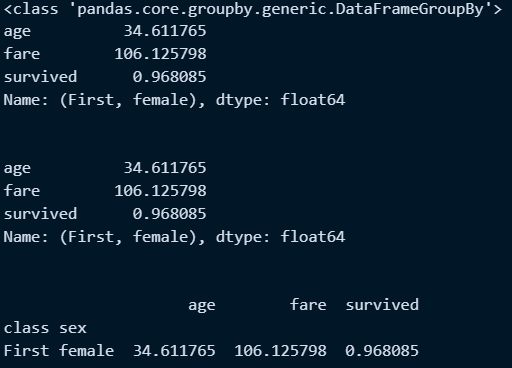
'Python > Pandas & numpy' 카테고리의 다른 글
| 판다스 : 전처리 기본 함수 요약모음 (1) | 2024.02.11 |
|---|---|
| 판다스 : 데이터 핸들링 예제 (0) | 2024.02.09 |
| 판다스 : 데이터 필드 형변환 (0) | 2024.02.08 |
| 판다스 : .numeric_only, groupby/get_group (0) | 2024.02.08 |
| 판다스 : .filter() 함수 (0) | 2024.02.08 |



