□ 타이타닉 데이터 핸들링
○ 데이터불러오기
import numpy as np
import seaborn as sns
import pandas as pd
titanic = sns.load_dataset('titanic')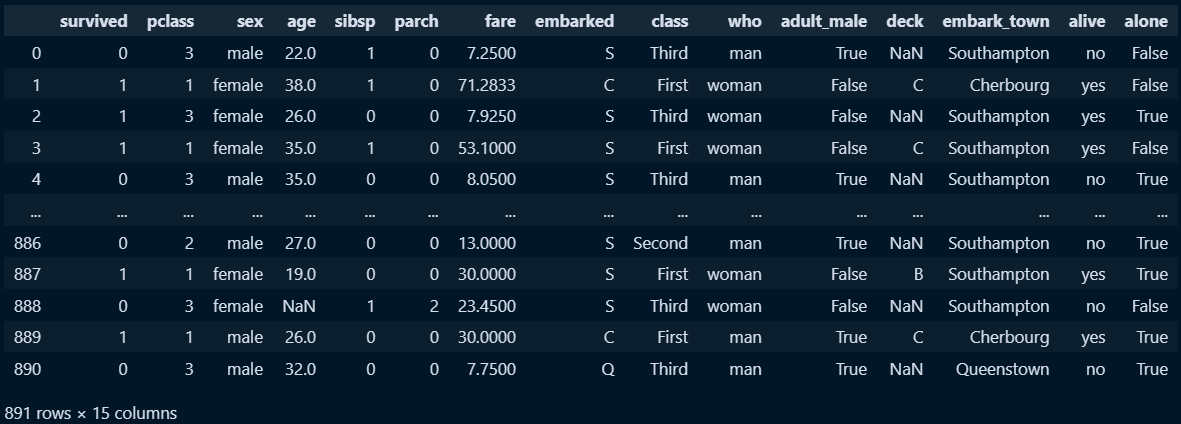
○ 특정필드 선정 및 셋지정
new_titanic = titanic[['age','sex','class','fare','survived']]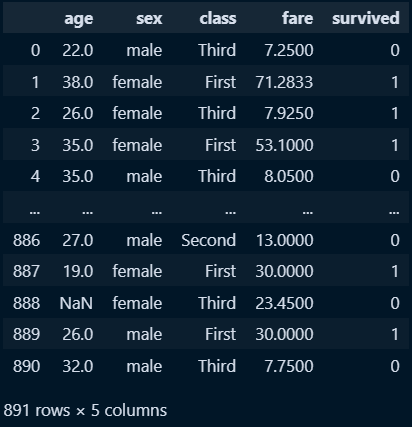
○ 특정필드 그룹바이 *그룹바이만 한다면 해당 데이터는 객체로써 존재함
grouped = new_titanic.groupby('class')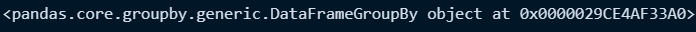
○ age 평균보다 아래인 데이터
new_titanic[new_titanic['age'] < new_titanic['age'].mean()]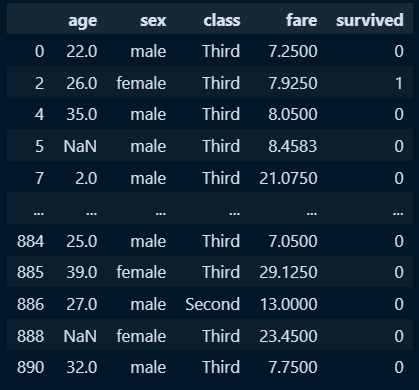
○ age의 표준편차를 구하고 해당 값으로 구성된 신규필드 생성
def z_score(x):
return (x - x.mean())/x.std()
new_titanic['z_score_new'] = grouped['age'].transform(z_score)
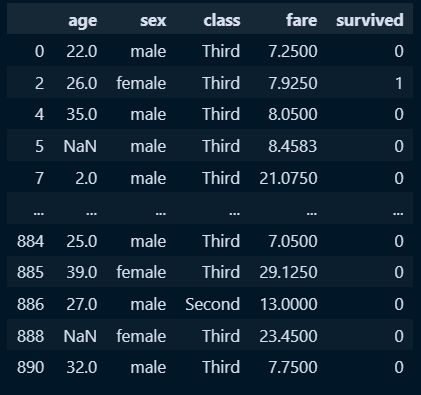
new_titanic
□ 기타 데이터 핸들링
○ 데이터 불러오기 및 첫행 필드명으로 적용되는 현상 방지하기 위해 header=None 사용
import numpy as np
import seaborn as sns
import pandas as pd
mpg = pd.read_csv('C:/python/DataScience/Data/data/python_data/mpg.csv', header = None)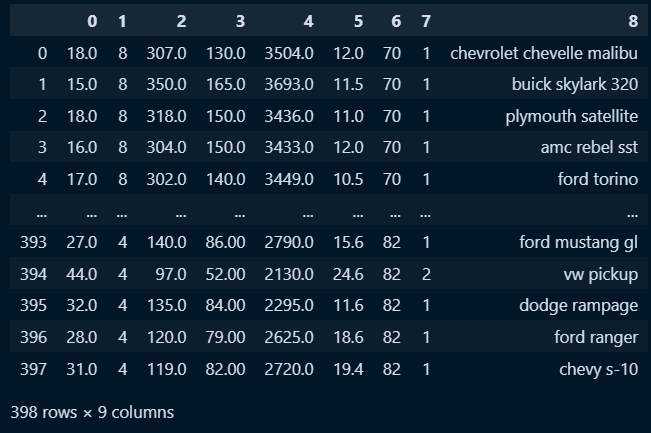
○ 컬럼명 변경
mpg.rename(columns={
0:'mpg',
1:'cyl',
2:'disp',
3:'power',
4:'weight',
5:'acce',
6:'year',
7:'origin',
8:'name'}, inplace=True)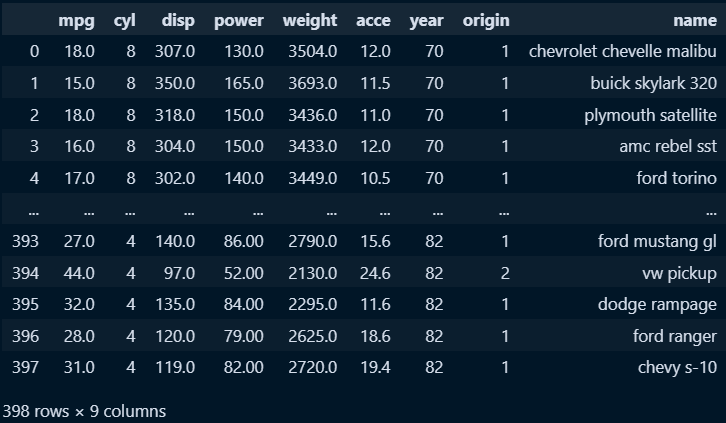
○ 컬럼별 속성파악
mpg.dtypes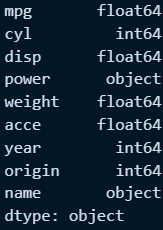
○ power 필드의 고유값 확인
a = mpg['power'].unique() #배열로 반환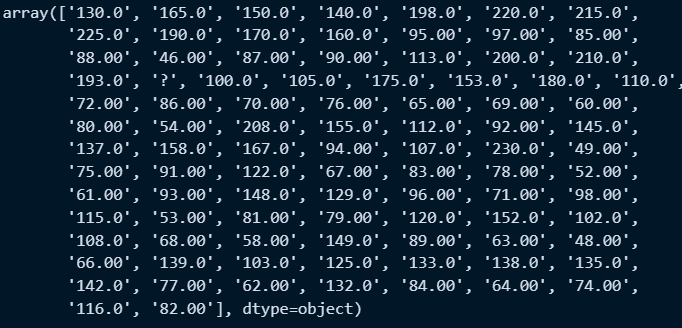
○ origin 값 중 1 > USA , 2 > EU, 3 > JAPAN 으로 변경 후 신규필드를 생성하여 채우기
def change_value(x):
if x == 1:
return 'USA'
elif x == 2:
return 'EU'
elif x == 3:
return 'JAPAN'
#셋함수적용
mpg['origin'] = mpg['origin'].apply(change_value)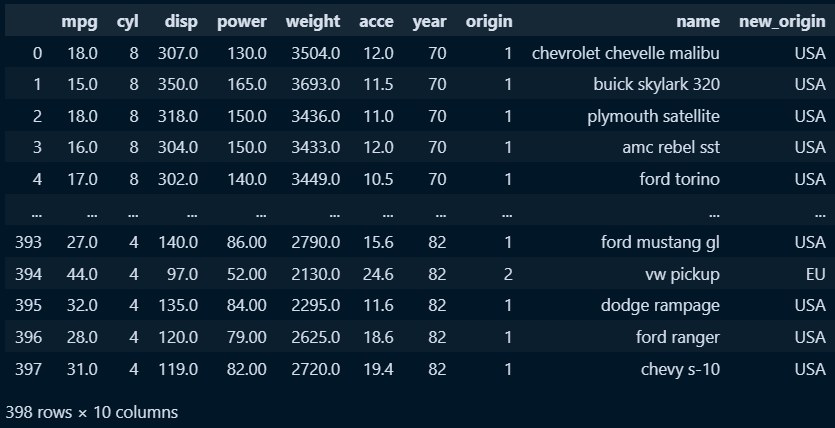
○ 특정 필드 타입을 범주형(category) 타입으로 변환
mpg['origin'] = mpg['origin'].astype('category')
'Python > Pandas & numpy' 카테고리의 다른 글
| Datetime & pd.to_datetime (1) | 2024.02.16 |
|---|---|
| 판다스 : 전처리 기본 함수 요약모음 (1) | 2024.02.11 |
| 판다스 : groupby, 멀티인덱스 활용 조회 (0) | 2024.02.08 |
| 판다스 : 데이터 필드 형변환 (0) | 2024.02.08 |
| 판다스 : .numeric_only, groupby/get_group (0) | 2024.02.08 |



