□ 함수는 그룹별로 계산된 결과를 원본 데이터프레임에 다시 병합하는 역할수행
□ 주로 그룹별로 계산한 평균, 합 등의 값을 각 행에 적용하고자 할 때 사용
□ 예제
○ 라이브러리 호출 및 데이터 불러오기
#라이브러리 호출
import pandas as pd
import numpy as np
#데이터 불러오기
df = pd.read_csv('C:/python/DataScience/Data/data/python_data/gapminder.tsv', delimiter='\t')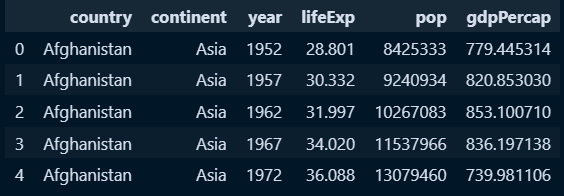
○ 함수정의 및 구룹화된 데이터 프레임에 transfom을 적용하여 값 조회
#함수정의 : 표준편차
def my_zscore(x):
return ((x - x.mean()) / x.std())
#시리즈반환 : year필드로 그룹화 후 표준편차 함수 lifeExp열적용
df1 = df.groupby('year')['lifeExp'].transform(my_zscore)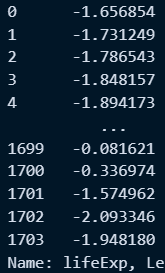
□ 예제심화
#라이브러리 불러오기
import numpy as np
import seaborn as sns
#데이터 불러오기
np.random.seed(42)
tips_10 = sns.load_dataset('tips').sample(10)
# total_bill 필드의 인덱스 4까지 값 NaN으로 변경
# np.random.permutation()함수를 뒤섞은 후에 n개만큼 indexing
tips_10.loc[
np.random.permutation(tips_10.index)[:4],'total_bill'
] = np.NaN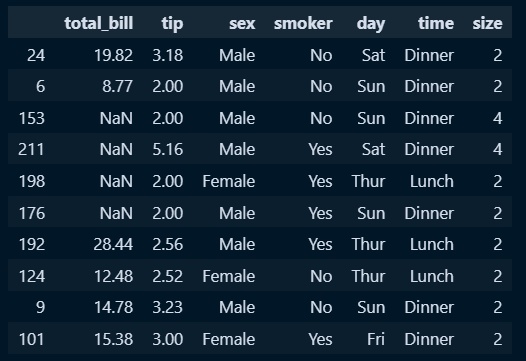
○ 함수와 transform기능을 활용해 새로운 필드에 값 채우기
#함수정의
def fillna_num(x):
avg = x.mean()
return x.fillna(avg)
#sex필드를 기준으로 total_bill 열 기준으로 정의한 함수를 적용하여 NaN값 채움
transform_field = tips_10.groupby('sex')['total_bill'].transform(fillna_num)
#transform과 함수를 바탕으로 생성된 시리즈를 바탕으로 새로운 필드 생성
tips_10['new_total_bill'] = transform_field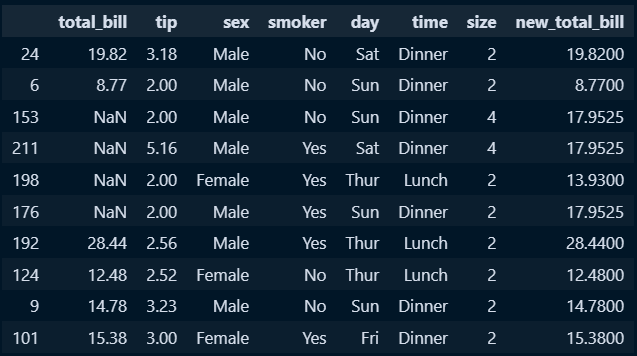
'Python > Pandas & numpy' 카테고리의 다른 글
| 판다스 : .numeric_only, groupby/get_group (0) | 2024.02.08 |
|---|---|
| 판다스 : .filter() 함수 (0) | 2024.02.08 |
| 판다스 : agg 심화 (0) | 2024.02.08 |
| 판다스 : 전처리 예제(feat. agg함수) (0) | 2024.02.08 |
| 판다스 : .apply() 함수 예제 (1) | 2024.02.08 |



