□ 데이터 프레임에 함수적용 등 다양한 방법으로 가공해보자

라이브러리 호출
from datetime import datetime
import pandas as pd
#현재년도 변수지정
current_year = datetime.now().year
#데이터프레임 생성
encore= [{'name': 'A', 'birth': '1999-06-27', 'mid': 95, 'fin': 85},
{'name': 'B', 'birth': '1997-06-27', 'mid': 85, 'fin': 80},
{'name': 'C', 'birth': '1998-06-27', 'mid': 10, 'fin': 30},
{'name': 'D', 'birth': '2000-06-27', 'mid': 73, 'fin': 90}]
df = pd.DataFrame(encore, columns = ['name', 'birth', 'mid', 'fin'])
○ 기존 두 칼럼(mid, fin)을 사용해서 total 칼럼을 생성
#총계산출 함수설정
def column_sum(col):
x = col[0]
y = col[1]
return x+y
#데이터셋 구축
two_df = df[['mid','fin']] #별도 데이터셋 구축
#.apply함수를 활용해 함수적용 및 행방향연산을 위해 axis=1 지정
new_data1 = two_df.apply(column_sum, axis=1)
#기존 데이터프레임에 total 필드 생성 및 값은 함수를 통해 나온 시리즈 값 적용
df['total'] = new_data1
○ 기존 칼럼(mid, fin)을 사용해서 average 칼럼을 생성
#평균산출 함수설정
def column_avg(col):
x = col[0] #필드간의 연산을 하고자할 때 필드개수만큼 변수지정 필요
y = col[1]
return (x+y)/2
#함수적용 데이터셋 구축
two_df = df[['mid','fin']]
#.apply함수를 활용해 함수적용 및 행방향연산을 위해 axis=1 지정
new_data2 = two_df.apply(column_avg, axis=1)
#기존 데이터프레임에 avg 필드 생성 및 값은 함수를 통해 나온 시리즈 값 적용
df['avg'] = new_data2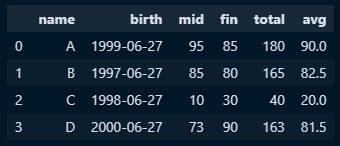
○ grade칼럼을 생성하시고, if~else문 사용 average 칼럼이 90이상이면 'A', 80 이상이면 'B' 70 이상이면 'C', 그렇지 않으면 'F'를 부여
#데이터셋 구축
one_df = df['avg']
#새로만들 필드의 값을 저장하기위한 리스트 변수
grade = list()
#반복문 진행 : 위에서 구축한 데이터셋에서 점수별 결과 지정을 위해 사용
for i in one_df:
if i >=90:
i = 'A'
elif i >=80:
i = 'B'
elif i >=70:
i = 'C'
else:
i = 'F'
grade.append(i) #점수별 결과를 추가할 리스트 변수
#데이터프레임에 신규필드 생성 후 값을 넣기위해 리스트를 시리즈로 형변환
grade = pd.Series(grade)
#기존 데이터프레임에 grade 필드 생성 및 값은 함수를 통해 나온 시리즈 값 적용
df['grade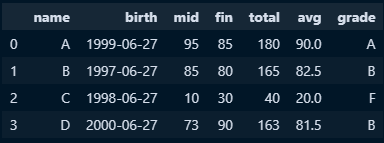
○ A,B,C이면 '합격' 그렇지 않으면 '불합격' 을 부여하는 함수를 만들고 apply 함수를 사용하여 grade1칼럼에 합격,불합격 부여
#성적에 따른 합격여부 반환 함수 지정
def select_result(x):
if x in ('A', 'B' 'C'):
return '합격'
else:
return '불합격'
#데이터셋 구축
three_df = df['grade']
#.apply함수를 활용해 함수적용
new_data3 = three_df.apply(select_result) #시리즈대상으로 함수 적용 했기에 시리즈반환
#기존 데이터프레임에 grade1 필드 생성 및 값은 함수를 통해 나온 시리즈 값 적용
df['grade1'] = new_data3
○ 출생년도만을 가져오는 함수를 만들고, apply 메서드를 사용하여 연월일의 정보에서 출생년도만 추출하여 year칼럼에 부여
#년도 파싱 및 추출 함수 지정
def birth_year(x):
year = x.split('-')[0]
return year
#데이터셋 구축
four_df = df['birth']
#.apply함수를 활용해 함수적용
new_data4 = four_df.apply(birth_year)
#기존 데이터프레임에 year 필드 생성 및 값은 함수를 통해 나온 시리즈 값 적용
df['year'] = new_data4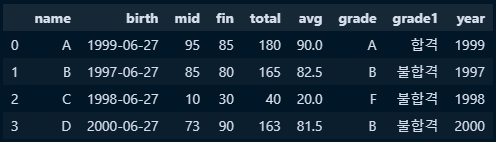
○ 이를 계산하는 함수를 만들고,apply 메서드를 사용하여 연월일의 정보에서 연도만 빼서 age칼럼에 부여
#나이 계산연산 함수 지정
def cal_age(x):
age = current_year - int(birth_year(x)) #연산을 위해 object 타입을 숫자형으로 형변환 진행
return age
#데이터셋 구축
fifth_df = df['year']
#.apply함수를 활용해 함수적용
new_data5 = fifth_df.apply(cal_age)
#기존 데이터프레임에 age 필드 생성 및 값은 함수를 통해 나온 시리즈 값 적용
df['age'] = new_data5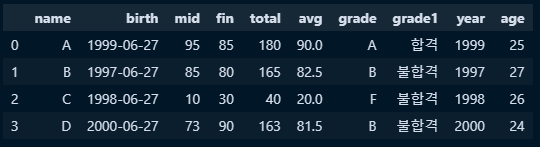
○ 나이가 22세 이상인 사람만 출력
df[df.age > 22]
○ 나이가 22세 이상인 사람만 성적이 A인사람
df[(df['age'] > 22) & (df['grade'] == 'A')]'Python > Pandas & numpy' 카테고리의 다른 글
| 판다스 : agg 심화 (0) | 2024.02.08 |
|---|---|
| 판다스 : 전처리 예제(feat. agg함수) (0) | 2024.02.08 |
| .apply() / .agg() 함수 (0) | 2024.02.07 |
| 판다스 : 다중데이터 불러오기 (0) | 2024.02.07 |
| 판다스 : .melt() 함수2 (한 필드의 고정 값이 2개 이상시) (1) | 2024.02.07 |



