□ 라이브러리 호출 및 데이터셋 불러오기(데이터는 seaborn 기본제공 데이터활용)
import pandas as pd
import seaborn as sns
#셋 구축
titanic = sns.load_dataset('titanic')
titanic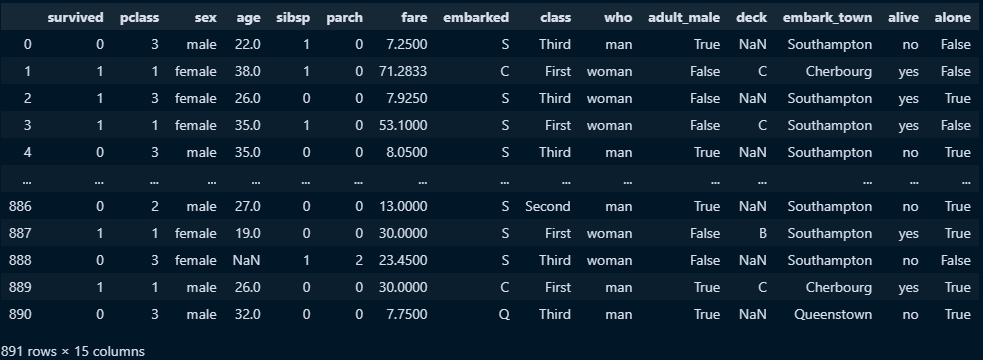
□ 전처리 : sex 필드의 데이터를 1, 0으로 전환해보자 → male = 1, female → 0
#시리즈 생성 : sex필드 및 데이터 값 활용
raw_field = titanic['sex']
#반복문을 통해 반환된 값을 담을 빈리스트 지정 / 해당리스트를 필드 값으로 적용
sex_list = list()
for v in raw_field:
if v=='male':
v = 1
else:
v = 2
sex_list.append(v)
# 반환된 데이터를 sex필드의 값으로 지정
titanic['sex'] = sex_list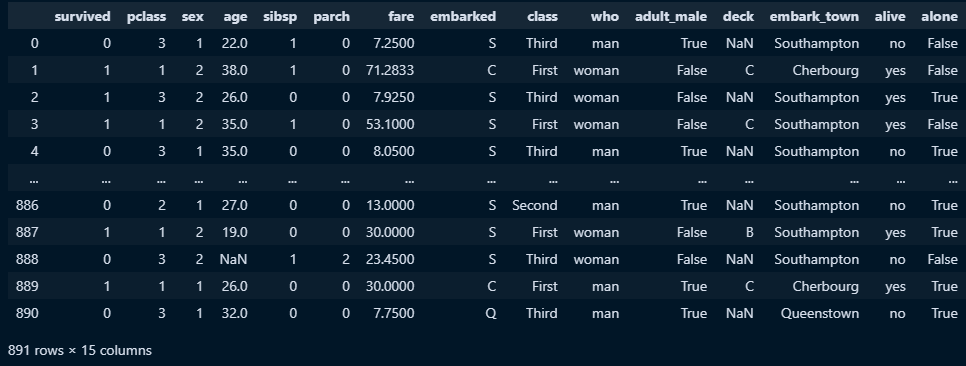
□ 데이터셋 구축
titanic_edit = titanic[['age','sex','class','fare','survived']]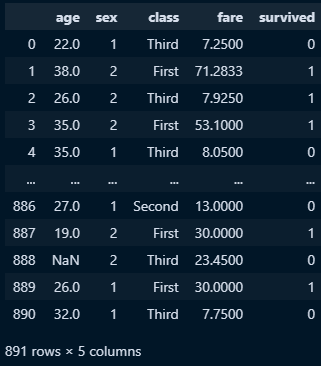
□ 데이터셋을 활용하여 필드별 그룹바이 및 표준편차 진행으로 생성한 시리즈를 신규 데이터프레임에 적용
#class 필드를 구룹화하여 age에대한 표준편차 : 시리즈 반환
age_std = titanic_edit.groupby('class')['age'].std()
#class 필드를 구룹화하여 sex에대한 표준편차 : 시리즈 반환
sex_std = titanic_edit.groupby('class')['sex'].std()
#class 필드를 구룹화하여 fare에대한 표준편차 : 시리즈 반환
fare_std = titanic_edit.groupby('class')['fare'].std()
#class 필드를 구룹화하여 survived에대한 표준편차 : 시리즈 반환
survived_std = titanic_edit.groupby('class')['survived'].std()
#새로운 데이터프레임 생성
new_titanic = pd.DataFrame()
#생성한 데이터프레임의 신규 필드들 지정 및 각 필드멸 데이터 지정
new_titanic['age_std'], new_titanic['fare_std'], new_titanic['survived_std'], new_titanic['sex_std'] = age_std, fare_std, survived_std, sex_std
new_titanic = new_titanic.reset_index()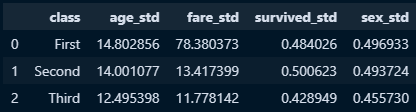
□ agg함수를 활용하여 생성된 시리즈들을 딕셔너리를 활용하여 새로운 데이터프레임으로 저장
#함수정의부 : 필드별 최대값과 최소값 연산을 반환하는 함수
def minmax(x):
return x.max() - x.min()
#딕셔너리 형태로 키는 필드명, 벨류는 필드의 값으로 저장. 아래 코드에서 벨류는 시리즈임
#agg함수를 사용하여 집계된 필드별 함수적용
second_dataframe = pd.DataFrame(
{'age_diff' : titanic_edit.groupby('class')['age'].agg(minmax),
'fare_diff' : titanic_edit.groupby('class')['fare'].agg(minmax),
'class_diff' : titanic_edit.groupby('class')['survived'].agg(minmax)
}
)
#인덱스 초기화로 평탄화 진행
second_dataframe.reset_index()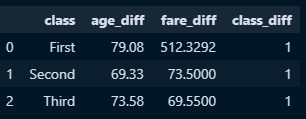
'Python > Pandas & numpy' 카테고리의 다른 글
| 판다스 : .transform() (0) | 2024.02.08 |
|---|---|
| 판다스 : agg 심화 (0) | 2024.02.08 |
| 판다스 : .apply() 함수 예제 (1) | 2024.02.08 |
| .apply() / .agg() 함수 (0) | 2024.02.07 |
| 판다스 : 다중데이터 불러오기 (0) | 2024.02.07 |



