□ 라이브러리 호출 및 데이터 불러오기
#라이브러리 호출
import pandas as pd
#파일불러오기
weather = pd.read_csv('C:/python/DataScience/Data/data/python_data/weather.csv')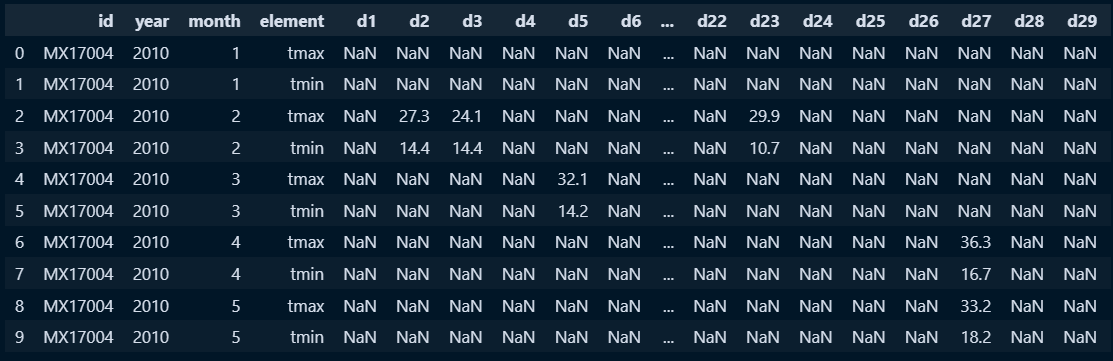
□ 멜트 1차 시도 : 특정 열 기준으로 멜트작업 진행
○ element 고정값이 2개(tmax, tmin)인 것을 확인
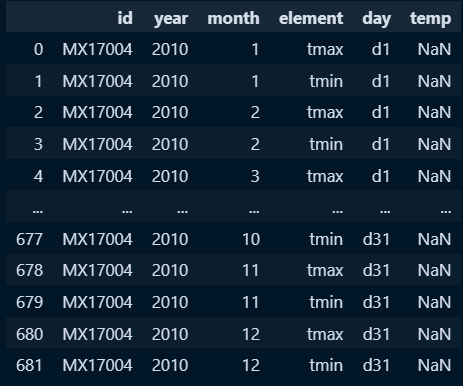
weather_melt = weather.melt(id_vars=['id','year','month','element'],
var_name = 'day',
value_name = 'temp'
)
□ 멜트 2차 시도 : 특정 열 기준으로 멜트 재작업 진행
○ .reset_index() : 인덱스 정리 + reset_index()를 활용하여 데이터 평탄화 진행
→ element 필드를 인덱스로 리셋 후 해당 열의 고정값이었던 것을 필드로 지정 및 연산진행
→ 이때 기존 데이터 값인 NaN이었던것은 무시되고 채워진 값을 기준으로 연산진행
weather_tidy = weather_melt.pivot_table(
index=['id','year','month','day'],
columns='element',
values='temp').reset_index() #인덱스 정리 reset_index()를 활용하여 데이터 평탄화 진행 이떄 null값은 자동으로 삭제됨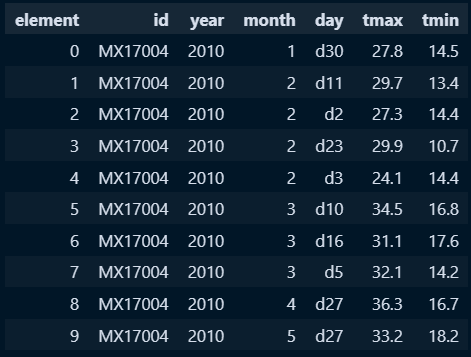
'Python > Pandas & numpy' 카테고리의 다른 글
| .apply() / .agg() 함수 (0) | 2024.02.07 |
|---|---|
| 판다스 : 다중데이터 불러오기 (0) | 2024.02.07 |
| 판다스 : 시리즈 (0) | 2024.02.04 |
| 판다스 : 타이타닉 데이터 결측값 처리 (0) | 2024.02.02 |
| 판다스 : 결측값 예제 (0) | 2024.02.02 |



