□ 목적 : 타이타닉 데이터에서 결측값을 처리해보자

import pandas as pd
#타이타닉 누락
titanic_file = pd.read_excel('C:/python/DataScience/Data/data/python_data/titanic.xls')
□ 예제
○ 불러온 데이터 프레임 정보확인 : .info()
#문제1 정보확인
titanic_file.info()
○ 필드별 결측값 개수 확인
- .count() : 필드별 데이터개수 집계(결측값을 포함시키진 않음)
- shape[0] : 행/열 정보를 나타내는 함수에서 [0] 인덱스를 활용해서 값 추출
#문제2 필드별 결측값 개수 구하기
a = titanic_file.count() #결측값을 제외한 집계
b = titanic_file.shape[0] #데이터프레임 총 행수
b
na_count = b - a #시리즈와 값 연산을 활용하여 총행수 - 결측제외 개수 로 필드별 결측값 개수 산출

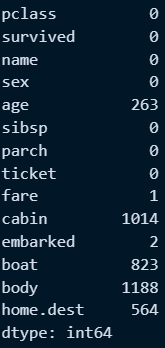
○ 특정 필드의 Nan 값을 평균값으로 변경
age_avg= titanic_file['age'].mean() #평균나이 구하기
titanic_eidit_age = titanic_file['age'].fillna(age_avg) #age열 시리즈의 결측값을 평균나이로 대체
titanic_file['age'] = titanic_eidit_age #기존 데이터프레임 age 열의 데이터를 결측값이 채워진 시리즈로 저장
titanic_file


○ age열의 데이터가 없는 행이 몇개인지 확인하고 없는 행을 모두 삭제
- .isna() : 데이터의 결측값 여부를 True, False로 반환
- .sum() : True 는 1이므로 True인 값들을 합산
- .dropna() : 결측값인 행 삭제
- .index() : 인덱스 번호 조회
- .iloc() : 인덱스 번호로 조건에 맞는 데이터 조회
titanic_file['age'].isna() #.isna()로 결측값여부조회
titanic_file['age'].isna().sum() #True 인것을 각 1로 총 합산
notnull_age = titanic_file['age'].dropna().index
notnull_age
titanic_file.iloc[notnull_age,:]




○ home.dest 의 최빈값이 큰 데이터로 16~27행 NaN값 대체하기
count_home = titanic_file['home.dest'].value_counts() #데이터값별 빈도수 조회
max_value = count_home.idxmax() #데이터값별 빈도수 데이터중 가장 많은 값의 인덱스 조회
titanic_smallgroup = titanic_file.iloc[16:28] #16~28행 범위만큼 데이터 추출 저장
#위에서 지정한 범위의 home.dest열의 널값을 데이터 최빈값으로 대체
notnull_home_dest = titanic_file['home.dest'].iloc[16:28].fillna(max_value)
#최빈값으로 널값을 대체한 시리즈를 적용 데이터프레임의 열의 값으로 저장
titanic_smallgroup['home.dest'] = notnull_home_dest




'Python > Pandas & numpy' 카테고리의 다른 글
| 판다스 : .melt() 함수2 (한 필드의 고정 값이 2개 이상시) (1) | 2024.02.07 |
|---|---|
| 판다스 : 시리즈 (0) | 2024.02.04 |
| 판다스 : 결측값 예제 (0) | 2024.02.02 |
| 판다스 : 결측값 (0) | 2024.02.02 |
| 판다스 : 중복개수 확인, 조건 False일 때 에러발생 코드 (0) | 2024.02.02 |



