□ 문제 1
○ 라이브러리 및 데이터 불러오기

import pandas as pd
import numpy as np
#라이브러리 호출
ebola = pd.read_csv('C:/python/DataScience/Data/data/python_data/country_timeseries.csv')
ebola.shape
○ 필드별 행수 집계(결측값 제외) : 데이터프레임명.count()
# 필드별 행수 집계(결측값 제외)
ebola.count()
○ NaN 결측값을 제외한 컬럼별 행 개수
- 데이터프레임명.shpa[0] 총 행수에서 결측값을 제외한 ebola.count() 를 빼면 잔여값이 결측값 개수임
# 필드별 행수 집계(결측값 제외)
ebola.count()
having_NaN = ebola.shape[0] - ebola.count()
having_NaN
○ Nan 결측값을 제외한 데이터가 있는 총 셀개수 구하기
# null 여부 파악
ebola.isnull() #셀별 True, False 반환
#np 라이브러리의 count_nonzero를 활용해 false, 즉 0값을 제외 하고 카운팅. True 1인 값이 있는 셀 개수 집계
np.count_nonzero(ebola.isnull())
print(np.count_nonzero(ebola.isnull()))
○ 빈도수 구하기 : value_counts(dropna = False 또는 True)
- False : 결측값 포함
ebola.Cases_Guinea.value_counts(dropna=False) #누락값 포함
- True : 결측값 제외
ebola.Cases_Guinea.value_counts(dropna=True) #누락값 제외
○ .fiila : 결측값 대체
a = ebola.iloc[:,0:5]
a.fillna(0)
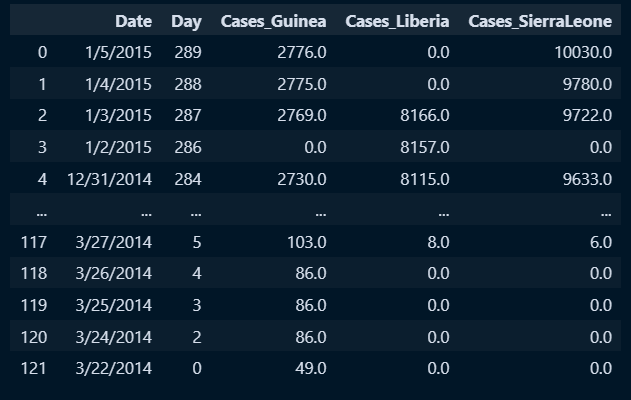
○ .ffill : 결측값 기준 위에 값으로 대체
ebola.iloc[:,0:5].head(10)
ebola.fillna(method='ffill').iloc[:,0:5].head(10)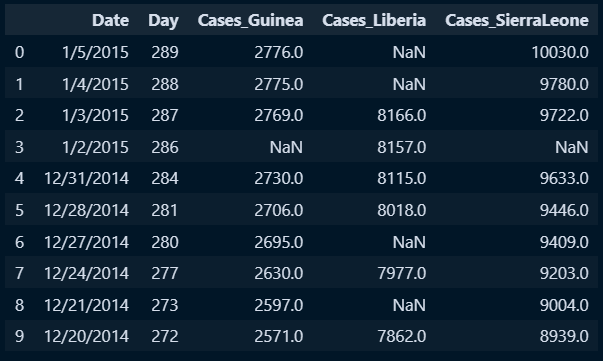

○ .bfill : 결측값 기준 아래 값으로 대체
ebola.iloc[:,0:5].head(10)
ebola.fillna(method = 'bfill').iloc[:,0:5].head(10)

○ .interpolate : 결측값 기준 위와 아래 값의 평균으로 대체
ebola.iloc[:,0:5].head(10)
ebola.interpolate().iloc[:,0:5]

'Python > Pandas & numpy' 카테고리의 다른 글
| 판다스 : 시리즈 (0) | 2024.02.04 |
|---|---|
| 판다스 : 타이타닉 데이터 결측값 처리 (0) | 2024.02.02 |
| 판다스 : 결측값 (0) | 2024.02.02 |
| 판다스 : 중복개수 확인, 조건 False일 때 에러발생 코드 (0) | 2024.02.02 |
| 판다스 : Merge (0) | 2024.02.02 |



