□ 같은 내용의 데이터지만 년도가 각자 다른 파일에 대하여 시각화 차트를 구현해보자
□ 작업진행 : 데이터별 전처리 → 필요 데이터 추출 → 시각화 틀(판)생성 및 추출된 데이터기반으로 시각화 그래프 생성
□ 세부내용
○ 라이브러리 호출
#라이브러리 호출
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False # 한글 깨짐 방지를 위해 호출
#한글표시 및 사용을 위해
f_path = 'C:/Windows/Fonts/malgun.ttf'
font_name = font_manager.FontProperties(fname = f_path).get_name()
rc('font', family = font_name)
○ 파일 불러오기 및 전처리 1

- header = 1 / header = 0
: header=None을 사용하면 첫 번째 행이 데이터로 처리되고 컬럼명이 자동으로 생성됨. 반면에 header=1을 사용하면 두 번째 행부터 데이터로 처리되고, 컬럼명은 자동으로 생성되지 않고 순서대로 숫자로 할당
- usecols = 'execel필드:excel필드'
: 원본 로우데이터에 csv 파일 기준 A, B, C~~~와 같은 열이름을 지정하여 불러올 범위 설정
- names 를 활용하여 불러온 데이터의 컬럼명을 별도 지정
#컬럼명 변수 지정
col_names = ['스트레스','스트레스남학생','스트레스여학생','우울감경험률','우울남학생','우울여학생','자살생각율','자살남학생','자살여학생']
#데이터 호출,
row_data = pd.read_excel("C:/python/DataScience/Data/data/python_data/mental.xls", header =1 , usecols='C:K',names = col_names)
row_data2 = pd.read_excel("C:/python/DataScience/Data/data/python_data/second_test_file.xls", header =1 , usecols='B:J',names = col_names)
○ 파일 불러오기 및 전처리 2
- inplace = True 해당 작업을 진행하면서 원본파일에 반영하겠다는 의미
#행추가 : 생성행의 값은 100에서 기본 불러온 데이터의 0행의 값을 뺀 값으로 채우겠다는 의미
row_data.loc[1] = 100 - row_data.loc[0]
row_data2.loc[1] = 100 - row_data2.loc[0]
#필드 생성 및 값 추가 : 총 행이 2행으로 값 2개 적재
row_data['응답'] = ['그렇다','아니다']
row_data2['응답'] = ['그렇다','아니다']
#생성된 응답 필드를 인덱스로 적용
row_data.set_index('응답', inplace = True) #inplace = True 원본에 반영하겠다
row_data2.set_index('응답', inplace = True) #inplace = True 원본에 반영하겠다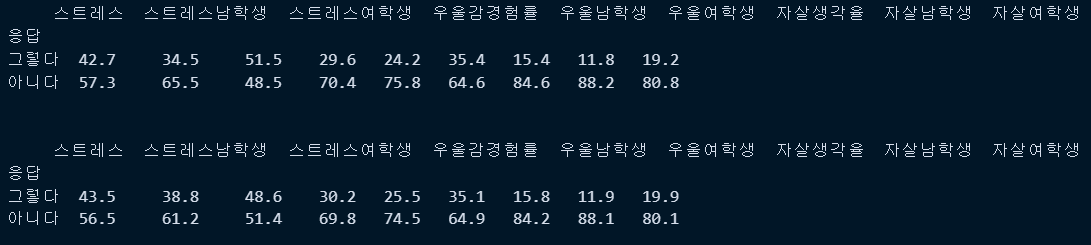
○ 시각화 틀(판)생성
# 틀생성
# 2행, 3열로 형성된 틀 / figsize로 틀 사이즈 지정
# ax = 그래프객체 의미함
f, ax = plt.subplots(2, 3, figsize=(16, 8))
○ 데이터 시각화 변환
# 첫 번째 서브플롯
row_data['스트레스'].plot.pie(explode=[0, 0.02], ax=ax[0, 0], autopct='%1.1f%%')
ax[0, 0].set_title('우울증을 경험한 적 있다.')
ax[0, 0].set_ylabel('')
# 두 번째 서브플롯
row_data['우울감경험률'].plot.pie(explode=[0, 0.02], ax=ax[0, 1], autopct='%1.1f%%')
ax[0, 1].set_title('스트레스를 받은적있음')
ax[0, 1].set_ylabel('')
# 세 번째 서브플롯
row_data['자살생각율'].plot.pie(explode=[0, 0.02], ax=ax[0, 2], autopct='%1.1f%%')
ax[0, 2].set_title('자살을 고민한적 있다')
ax[0, 2].set_ylabel('')
# 네 번째 서브플롯
row_data2['스트레스'].plot.pie(explode=[0, 0.02], ax=ax[1, 0], autopct='%1.1f%%')
ax[1, 0].set_title('우울증을 경험한 적 있다.')
ax[1, 0].set_ylabel('')
# 다섯 번째 서브플롯
row_data2['우울감경험률'].plot.pie(explode=[0, 0.02], ax=ax[1, 1], autopct='%1.1f%%')
ax[1, 1].set_title('스트레스를 받은적있음')
ax[1, 1].set_ylabel('')
# 여섯 번째 서브플롯
row_data2['자살생각율'].plot.pie(explode=[0, 0.02], ax=ax[1, 2], autopct='%1.1f%%')
ax[1,2].set_title('자살을 고민한적 있다')
ax[1,2].set_ylabel('')
○대제목 지정
#대제목
plt.suptitle("서울시 청소년 정신건강 비교 2018년-2022년")
#제목과 시각화영역 간격 좁히기
plt.tight_layout()
'Portfolio & Toy-Project' 카테고리의 다른 글
| 프로젝트 : 부산항만공사 서비스 제안관련 데이터분석-1 (0) | 2024.03.11 |
|---|---|
| 판다스 : .melt() 함수1 (0) | 2024.02.07 |
| 타이타닉 데이터 전처리 및 시각화 (1) | 2024.02.06 |
| 임의 페이지 텍스트 크롤링 및 엑셀저장 (1) | 2024.01.30 |
| 파이썬(셀레니움)자동화_(구글 스프레드시트/카카오톡API&엑셀저장) (1) | 2024.01.25 |



