□ 기본설명 및 함수기능

□ 예제 1
○ 라이브러리 호출 및 파일 불러오기를 통한 데이터 프레임 생성
#라이브러리호출
import pandas as pd
#csv불러오기 및 데이터프레임 생성
person = pd.read_csv('C:/python/DataScience/Data/data/python_data/survey_person.csv')
site = pd.read_csv('C:/python/DataScience/Data/data/python_data/survey_site.csv')
survey = pd.read_csv('C:/python/DataScience/Data/data/python_data/survey_survey.csv')
visited = pd.read_csv('C:/python/DataScience/Data/data/python_data/survey_visited.csv')
○ 1:1병합

# 1:1 병합 = innerjoin과 같음
o2o_merge = site.merge(visited_subset, left_on= 'name', right_on='site') #머지대상 데이터프레임, 좌측 공통필드, 우측 공통필드
o2o_merge
○ 다대다 병합 : 모두 quant 열에 중복값이 있으므로 다대다 병합 일어남

ps_vs = ps.merge(vs, left_on = ['quant'], right_on = ['quant'])○ 다대다 병합 : 열목록들을 활용하여 병합

ps_vs = ps.merge(vs, left_on=['ident', 'taken', 'quant', 'reading'], right_on=['person', 'ident', 'quant', 'reading'])
□ 예제 2
○ 데이터 불러오기 및 데이터프리임 생성
df1 = pd.read_excel('C:/python/DataScience/Data/data/python_data/s_price.xlsx')
df2 = pd.read_excel('C:/python/DataScience/Data/data/python_data/s_valuation.xlsx')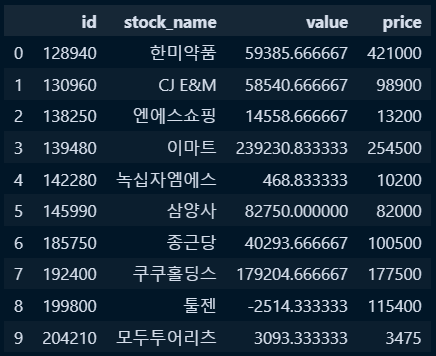

○ id 필드로 innerjoin
df1_df2 = df1.merge(df2, left_on='id', right_on='id')
○ outer 머지
df1_df2_outer = df1.merge(df2, left_on='id', right_on='id', how = 'outer')
○ left 머지
df1_df2_left = df1.merge(df2, left_on=['stock_name'], right_on=['name'], how='left')
○ right 머지
df1_df2_right = df1.merge(df2, left_on=['stock_name'], right_on=['name'], how = 'right')
○ 조건에 의한 데이터 조회 : 가격이 58,000원 미만

over_price = df1[df1['price']<58000]'Python > Pandas & numpy' 카테고리의 다른 글
| 판다스 : 결측값 (0) | 2024.02.02 |
|---|---|
| 판다스 : 중복개수 확인, 조건 False일 때 에러발생 코드 (0) | 2024.02.02 |
| 판다스 : 예제(concat, 정규표현) (0) | 2024.02.02 |
| 판다스 : concat (0) | 2024.02.02 |
| 판다스 : 컬럼타입 확인, 판다스 날짜컬럼 변환, 시리즈 컬럼 추가 (0) | 2024.02.02 |



