□ 필드간 연산
○ 변수명[필드명].sum()
○ 변수명[필드명].mean() 등
□ 정렬
○ 오름차순 : 변수명 = pd.sort_values(by = 필드명, absendng = True)
○ 내림차순 : 변수명 = pd.sort_values(by = 필드명, absendng = False)
□ 컬럼추가
○ 변수명[신규필드명] = 시리즈 데이터
□ 예제 : 평균 구하기, 평균보다 큰데이터, 정렬
○ 데이터프레임생성

#데이터프레임 생성
scientists = pd.read_csv('C:/Users/romangrism/Desktop/Datasicence/Data\data/python_data/scientists.csv')
scientists.head()
○ 평균 & 평균보다 큰 데이터
- 변수명[필드명].mean()
- 변수명[변수명[필드명] > 변수명[필드명].mean()]

#평균나이
scientists['Age'].mean()
#평균나이보다 많은 사람
scientists[ scientists['Age']> scientists['Age'].mean() ]
○ 오름차순&내림차순
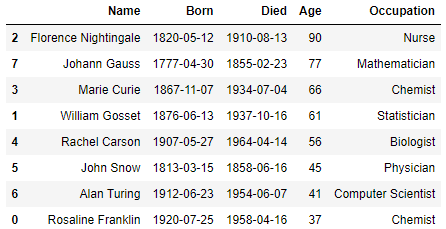
#나이 오름차순
scientists.sort_values(by = 'Age', ascending = True)
#나이 내림차순
scientists.sort_values(by = 'Age', ascending =False)
□ 예제 : 컬럼추가, 정렬
○ 데이터프레임(csv) 불러오기

cctv_df = pd.read_csv('C:/Users/romangrism/Desktop/Datasicence/Data\data/python_data/01. CCTV_in_Seoul.csv')
cctv_df.head()
○ 정렬

# #cctv가 가장 적은 5개구 : 오름차순
cctv_df.sort_values(by='소계', ascending = True).head()
# #cctv가 가장 많은 5개구 : 내림차순
cctv_df.sort_values(by='소계', ascending = False).head()
○ 신규컬럼추가 & 값은 시리즈 데이터 저장

#증가율 컬럼추가
cctv_df['increas_rate'] = ((cctv_df['2015년'] + cctv_df['2016년'])/cctv_df['2014년'])*100
cctv_df
□ 예제 : 딕셔너리를 활용해 데이터프레임 생성, 정렬, 특정 행 추출, 특정 필드 추출
○ 데이터프레임 생성

student_play = pd.DataFrame({
'파이썬' : [90,80,70,60],
'장고' : [98,89,95,95],
'오라클': [85,95,100,100],
'HTML' : [100,90,90,90]},
index=['연아','순아','인아','민아']) #인덱스 설정
student_play
○ 특정필드 기준 내림차순

#장고점수 내림차순
student_play.sort_values(by='장고', ascending = False)
○ 특정 필드 추출/표시

# #파이썬, 오라클, HTML 컬럼만 표시
student_play[['파이썬','장고','HTML']]
○ 특정 행 정보 추출

#인아 행만 추출
student_play.loc['인아']
○ 특정 필드 추출/표시

#파이썬, HTML 추출
student_play[['파이썬','HTML']]
□ 예제 : 데이터 불러올때 데이터 첫행으로 표시방지, 컬럼명 지정, 집계, 조건에의한 데이터 조회
○ csv 불러올때 첫행 데이터가 컬럼명으로 표시 방지

#파일열때 데이터 첫행이 필드명으로 들어오는것 방지 (header = None)
no_df = pd.read_csv('C:/Users/romangrism/Desktop/Datasicence/Data\data/python_data/f_list_no_head.csv', header=None)
no_df
○ 컬럼명 지정

#컬러명 넣기
no_df.columns = ['name','age','job']
no_df
○ 특정 조건에 의한 데이터 조회

#30살 이상인 인원
no_df[no_df['age']>=30]
#30살 이상이고 이름이 Nate인 행
no_df[(no_df['age']>=30) & (no_df['name']=='Nate') ]
#30살이 아닌 인원들만조회
no_df[no_df['age']!=30]
#이름이 Jenny 또는 Brian인 사람
no_df[(no_df['name']=='Jenny')|(no_df['name']=='Brian')]
○ 특정 필드만 표시

#컬러명 넣기
no_df.columns = ['name','age','job']'Python > Pandas & numpy' 카테고리의 다른 글
| 판다스 : concat (0) | 2024.02.02 |
|---|---|
| 판다스 : 컬럼타입 확인, 판다스 날짜컬럼 변환, 시리즈 컬럼 추가 (0) | 2024.02.02 |
| 판다스 : 데이터프레임 생성 및 필드명/데이터 조회 (0) | 2024.02.01 |
| 판다스 : 시리즈, 데이터프레임 생성 (0) | 2024.01.31 |
| 판다스 : 기초통계 (0) | 2024.01.31 |



