□ 시리즈 *시리즈를 만들때 데이터와 인덱스 수 가 반드시 일치해야함
#형식
변수명 = pd.Series(data=[데이터1,데이터2], index=[데이터1,데이터2])
#예제
import pandas as pd
my_s = pd.Series(data =['banana',42], index=['person','Who'])
idx = my_s.index #인덱스만 저장
val = my_s.values #벨류(데이터)만 저장


□ 딕셔너리
#형식
변수명 = pd.Dataframe(
{
키 : 벨류,
키 : 벨류,
키 : 벨류
}
)
#예제(1) 키값은 필드명으로 벨류값은 필드별 데이터로 저장
scientists_1 = pd.DataFrame({
'name' : ['Rosaline Flankine','William Gosset'],
'Occupation' : ['Chemist','Stastician'],
'Born' : ['1920-07-25','1876-06-13'],
'Died': ['1958-04-16','1937-10-16'],
'Age' : [37,61]})
#예제(2) 키값은 필드명으로 벨류값은 필드별 데이터로 저장, 단 인덱스는 문자로 별도지정
# └ 인덱스를 문자열로 지정했으므로 loc로 데이터 조회 가능
scientists = pd.DataFrame({
'Occupation' : ['Chemist','Stastician'],
'Born' : ['1920-07-25','1876-06-13'],
'Died': ['1958-04-16','1937-10-16'],
'Age' : [37,61]},
index=['Rosaline Flankine','William Gosset'], #인덱스 설정
columns = ['Occupation', 'Born', 'Age', 'Died']) #필드명 순서지정
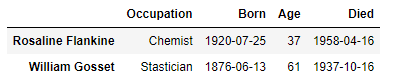
'Python > Pandas & numpy' 카테고리의 다른 글
| 판다스 : 필드집계, 정렬(오름/내림차순), 컬럼추가 (0) | 2024.02.02 |
|---|---|
| 판다스 : 데이터프레임 생성 및 필드명/데이터 조회 (0) | 2024.02.01 |
| 판다스 : 기초통계 (0) | 2024.01.31 |
| 판다스 : loc와 iloc (0) | 2024.01.31 |
| csv 파일 불러오기 및 정보확인 (0) | 2024.01.31 |



