□ K-means(평균) 알고리즘
○ 평균값이 클러스터 중심에 위치하기 때문에 클러스터 중심 또는 센트로이드라고 부름
○ 무작위로 k개의 클러스터 중심을 정함
○ 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 클러스터의 샘플로 지정
○ 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경
○ 클러스터 중심에 변화가 없을때까지 2번으로 돌아가 반복
□ 코드
**비지도학습이라 fit 과정에서 타겟데이터를 사용하지 않음.
○ 데이터 로드
#데이터 로드
import numpy as np
fruits = np.load("C:/dPython/fruits_300.npy")
fruits_2d = fruits.reshape(-1,100*100) #차원죽소를 통한 2차원 변경 for 모델훈련을 위해
fruits_2d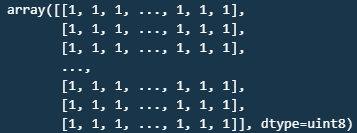
○ 모델생성
#모델생성
from sklearn.cluster import KMeans
km = KMeans(n_clusters = 3, random_state = 42) #클러스터 3개만들기
km.fit(fruits_2d) #모델학습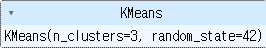
○ 레이블 확인 .labels_ : 데이터별 라벨부여
#데이터에대한 라벨
print(km.labels_)
#라벨별 개수 확인
print(np.unique(km.labels_, return_counts=True))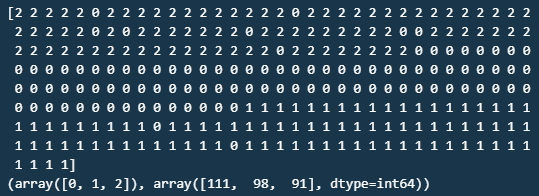
○ 데이터 라벨 부여작업이 끝난 후 데이터별 시각화
- 라벨이 0인 것만 시각화를 해보니 파인에플이 나옴(일부 사과와 바나나가 있긴함)
import matplotlib.pyplot as plt
import numpy as np
#함수정의
def draw_fruits(arr, ratio=0.5): #figsize는 ratio매개변수에 비례하여 커짐
n = len(arr) #n 샘플개수
rows = int(np.ceil(n/10)) #한줄에 10개씩 이미지 그리기. 샘플 개수를 10으로 나누어 전체 행 개수 계산
cols = n if rows < 2 else 10
fig, axs = plt.subplots(rows, cols, figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i * 10 + j < n:
axs[i,j].imshow(arr[i*10 + j], cmap="gray_r")
axs[i,j].axis('off')
plt.show()
draw_fruits(fruits[km.labels_==0])
- 라벨이 1인 것을 시각화하니 바나나가 나옴
draw_fruits(fruits[km.labels_==1])
- 라벨이 2인것을 확인하니 사과가 나옴
draw_fruits(fruits[km.labels_==2])
- 클러스터 중심값을 기반으로 시각화를 해보니 파인에플, 바나나, 사과의 형태가 그려짐
draw_fruits(km.cluster_centers_.reshape(-1,100,100), ratio=3)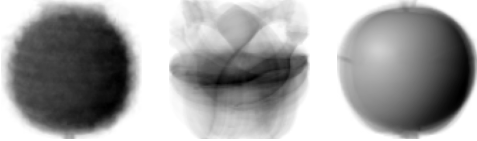
- 클러스터 중심값을 기반의 평균값
print(km.transform(fruits_2d[100:101]))
- 100번째 과일에 대한 예측진행
print(km.predict(fruits_2d[100:101]))
- 클러스터 반복회수 파악 : .n_iter_
print(km.n_iter_)
□ 최적의 k 찾기
○ k-평균 알고리즘은 클러스터 중심과 클러스터에 속한 샘플사이의 거리를 잴 수 있는데 이를 이너셔(inertial)라고 부름
○ 거리의 제곱 합이 이너셔임
○ 이너셔는 클러스터에 속한 샘플이 얼마나 가깝게 모여 있는지를 나타내는 값임
○ 일반적으로 클러스터 개수가 늘어나면 클러스터 개개의 크기는 줄어들기 때문에 이너셔도 줄어듬.
○ 클러스터 중심에 변화가 없을때까지 2번으로 돌아가 반복
○ 클러스트 개수를 증가시키면서 이너셔를 그래프로 그리면 감소하는 속도가 꺾이는 지점이 최적의 클러스터 K 가있는 부분임. 이 방법이 엘보우방법임.
inertia = []
for k in range(2,7):
km = KMeans(n_clusters=k, n_init="auto", random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_)
plt.plot(range(2,7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()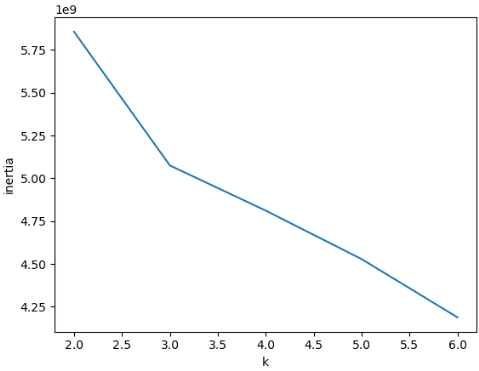
'Python > 머신러닝+딥러닝 Ⅰ' 카테고리의 다른 글
| 비지도학습 : 군집 알고리즘 기본 (0) | 2024.03.26 |
|---|---|
| Ensemble Model (0) | 2024.03.25 |
| 교차검증 (1) | 2024.03.22 |
| Decision Tree(결정트리 알고리즘) (0) | 2024.03.22 |
| 확률적경사하강법 (1) | 2024.03.22 |



