□ 로지스틱회귀란 LinearRegression에서 발전된 모델로 분류에 사용되는 모델임.
□ 이진분류인가 또는 다중분류인가에 따라 시그모이드 함수와 소프트맥스 함수를 적용하여 분류된 타겟에대한 확률을 출력함.

□ 예제
○ 데이터 호출
#라이브러리 및 데이터호출
import pandas as pd
wine = pd.read_csv("https://bit.ly/wine_csv_data")
wine.head()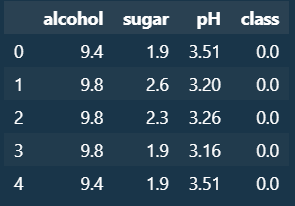
○ 데이터 EDA
#데이터 EDA
print(wine.info())
print(wine.describe())
○ 인풋/타겟 데이터 분리
#데이터 분리 : 인풋, 타겟
data = wine[["alcohol", "sugar", "pH"]].to_numpy() #셋 배열로변환
target = wine["class"].to_numpy()
○ 트레인, 테스트 데이터 분리
#트레인, 테스트 데이터 분리
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
print(f"트레이닝 데이터 형태 : {train_input.shape}")
print(f"트레이닝 데이터\n{train_input}")
print("\n")
print(f"테스트 데이터 형태 : {test_input.shape}")
print(f"테스트 데이터\n{test_input}")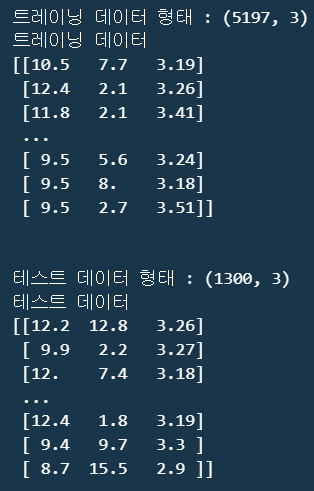
○ 데이터 스케일링
#데이터 스케일링 : 데이터간의 컬럼별 단위, 수치 차이로 발생하는 오차를 줄이기위한 전처리 기법으로
#-StandardScaler : (data - 평균)/표준편차
#-minmaxScaler : 최소값과 최대값 사이의 범위로 스케일링하는 머신러닝에서 널리 사용되는 전처리 기법 중 하나입니다. 이를 사용하면 데이터를 0과 1 사이의 범위로 변환함
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
print(f"트레이닝 데이터 스케일링 전\n{train_input}")
print(f"트레이닝 데이터 스케일링 후\n{train_scaled}")
print("\n")
print(f"트레이닝 데이터 스케일링 전\n{test_input}")
print(f"트레이닝 데이터 스케일링 후\n{test_scaled}")
○ 로지스틱회귀 모델생성 및 학습
#로지스틱 회귀 모델생성 및 학습
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression() #모델객체 생성
lr.fit(train_scaled, train_target)
print(f"트레이닝 점수\t:\t{lr.score(train_scaled, train_target)}")
print(f"테스트 점수\t:\t{lr.score(test_scaled, test_target)}")
※ 트레이닝, 테스트 정확도 점수가 낮게나옴.
※ 이러한 과정을 일일히 이유를 문서(보고서) 작성하기에도 버거우며, 어떠한 근거로 분류가 되었는지 비전공자 또는 유관 부서 종사자에게 설명하는 데 어느정도 제한이 생김.
※ 이에 따라 분류 모델 중 Decision Tree를 사용함.
- Decision Tree에서의 최상위 노드를 루트노드라 부르며 하위에 달린 노드를 리프노드라고 부름.
- 노드는 결정트리를 구성하는 핵심 요소임.
- 가지는 테스트의 결과(True,False)를 나타내며 일반적으로 하나의 노드는 2개의 가지를 가짐.
#결정트리 모델 생성 및 학습
from sklearn.tree import DecisionTreeClassifier
#모델생성
dt=DecisionTreeClassifier(random_state=42)
#학습
dt.fit(train_scaled, train_target)
#점수
print(f"트레이닝 점수\t:\t{dt.score(train_scaled, train_target)}")
print(f"테스트 점수\t:\t{dt.score(test_scaled, test_target)}")
○ Decision Tree 시각화 : plot_tree
#디시즌트리 시각화
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
○ Decision Tree 재시각화 : plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth= 1, filled=True, feature_names=["alcohol", "sugar", "pH"]) #max_depth = 나무깊이, filled = 노드색, feature_names = 속성
plt.show()
※ Gini(지니불순도)
- 결정트리에 지정한 조건에서 다음 노드로 분할시 기준을 정하는 것으로, 쉽게말해 한쪽으로 얼마나 쏠렸는가를 나타내는 척도임.
- 수치가 높을수록 양쪽으로 균등하게 분리되고, 낮을수록 한쪽으로 쏠려 명확히 분리됨.
○ Decision Tree 재학습 : 깊이 파라미터 조정
#모델생성
dt = DecisionTreeClassifier(max_depth=3, random_state=42) #깊이 3으로 지정
#모델합성
dt.fit(train_scaled,train_target)
print(f"트레이닝 점수\t:\t{dt.score(train_scaled, train_target)}")
print(f"테스트 점수\t:\t{dt.score(test_scaled, test_target)}")
○ Decision Tree 재시각화 : plot_tree(나무깊이, filled = 노드색, feature_names = 속성)
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=["alcohol", "sugar", "pH"]) #max_depth = 나무깊이, filled = 노드색, feature_names = 속성
plt.show()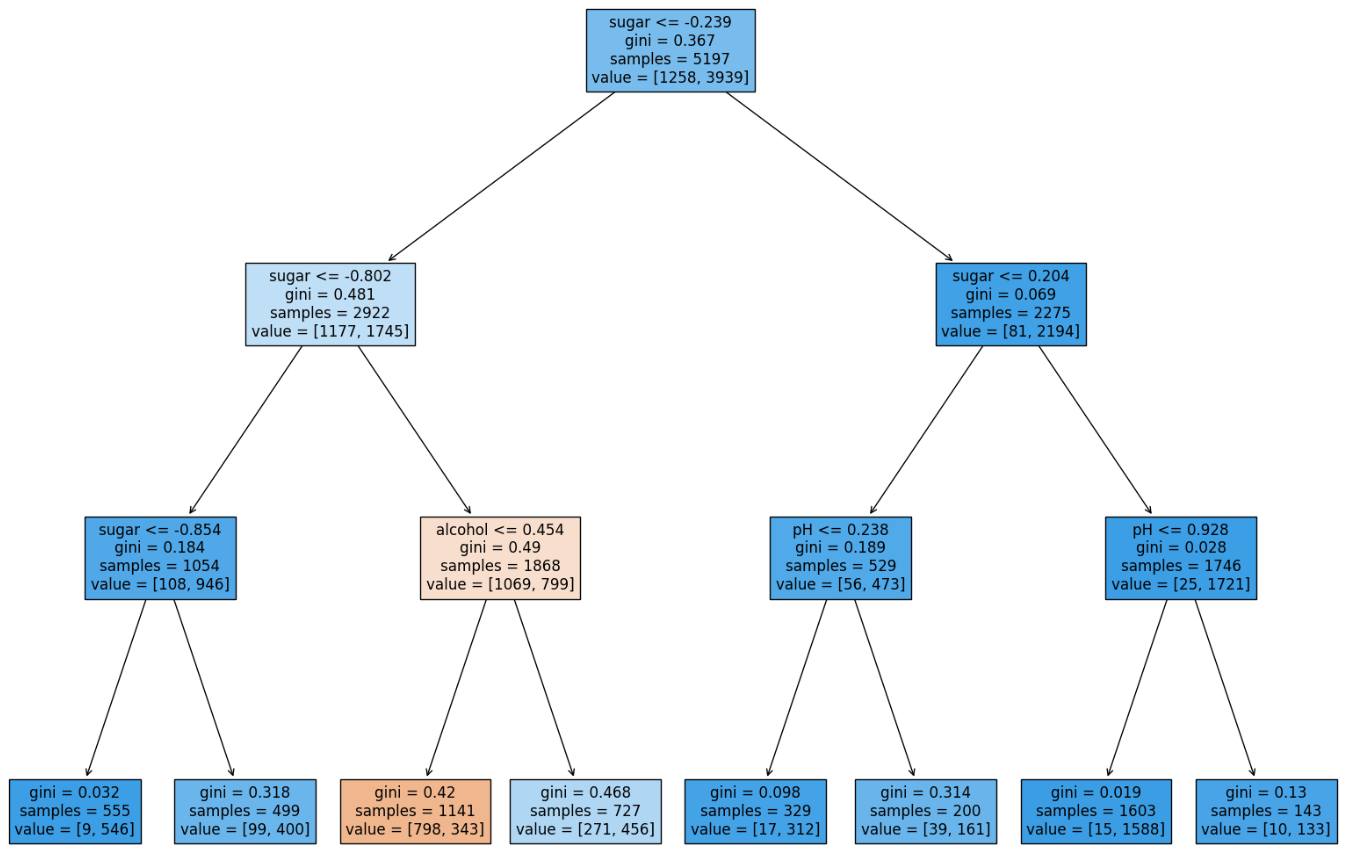
※ 트레이닝 데이터 셋에서 정한 속성중 Decision Tree가 중요시 생각하고 기준으로 하는 독립변수(컬럼)확인은 feature_importances_ 로 나타낼 수 있음
○ 모델에서 지정한 속성 및 분류 기준에 중점을 둔 속성 확인
print(dt.feature_names_in_)
#출력값 : alcohol, sugar, pH
print(dt.feature_importances_)
'Python > 머신러닝+딥러닝 Ⅰ' 카테고리의 다른 글
| Ensemble Model (0) | 2024.03.25 |
|---|---|
| 교차검증 (1) | 2024.03.22 |
| 확률적경사하강법 (1) | 2024.03.22 |
| Logistic_KNN (0) | 2024.03.22 |
| 규제(L1, L2)와 Ridge, Lasso (0) | 2024.03.15 |



