□ 단순 시각화를 위해서는 plotly 만 사용
○ chart_studio.plotly : Plotly 그래프를 생성하고 온라인으로 공유하는 데 사용되는 Plotly의 라이브러리임.
○ plotly.offline: Plotly : 그래프를 오프라인(로컬에서 실행) 모드로 사용하는 데 필요한 라이브러리임. plotly.offline를 사용하면 오프라인에서도 Plotly 그래프를 생성하고 시각화할 수 있음
○ cufflinks: Pandas 데이터프레임을 사용하여 간단하게 Plotly 그래프를 생성하는 데 사용되는 라이브러리임. cufflinks를 사용하면 Pandas 데이터프레임에 대해 쉽게 시각화할 수 있음
#라이브러리 호출
import chart_studio.plotly as py
import plotly.offline as pyo
import cufflinks as cf
import plotly.graph_objects as go
#Cufflinks를 오프라인 모드로 설정
cf.go_offline(connected=True)
□ 그래프 종류 조회
cf.help()
□ boxplot 시각화
○ 상자(Box): 데이터의 중간 50%를 나타냄. 상자는 Q1(하위 사분위수, 25%)에서 Q3(상위 사분위수, 75%) 사이의 데이터를 표시하며, 상자의 중앙에는 중간값이 표시됨.
○ 수염(Whisker): 상자에서 상위 사분위수와 하위 사분위수를 벗어난 최소값과 최대값을 나타냄. 일반적으로 1.5배 사분위 범위(IQR, Interquartile Range) 이내의 값은 수염으로 연결되지 않고 이상치로 간주됨.
○ 이상치(Outliers): 수염 바깥에 있는 개별 데이터 포인트로, 일반적인 데이터 분포에서 벗어난 극단적인 값들을 나타냄.
#데이터 프레임생성
df = pd.DataFrame({
"A":[10,20,30,40,50,60,70],
"B":[40,50,60,70,80,90,130]
})
# Cufflinks의 iplot 메서드를 사용하여 boxplot 그림생성.
#df.iplot(kind='box')
○ 라이브러리 plotly 사용 : 단순 시각화 그래프를 만들시
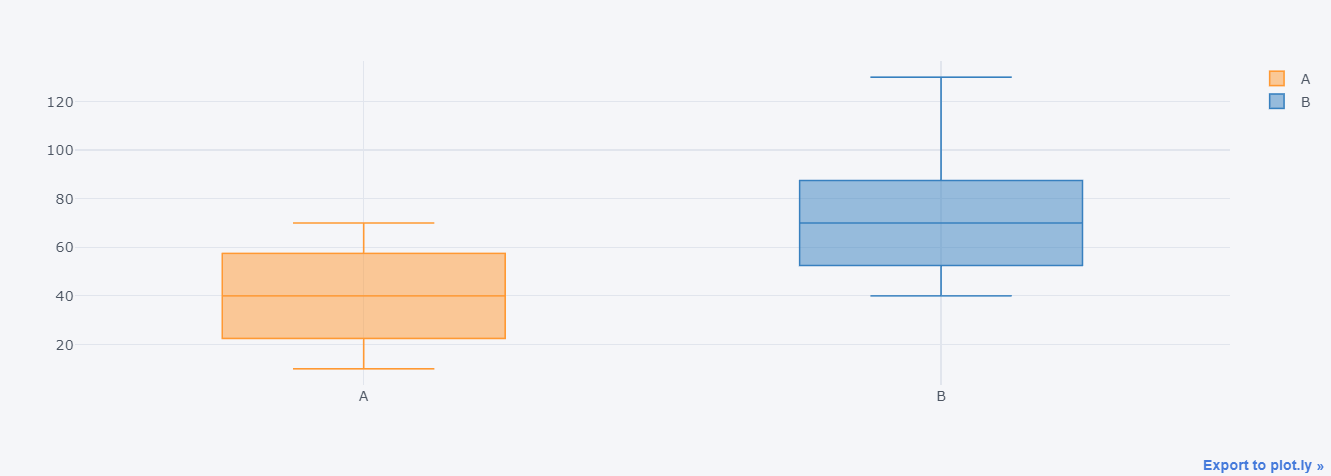
○ 라이브러리 plotly.graph_objects 사용 : 시각화 그래프의 세부조정을 만들기 위해 사용
#객체판 생성
fig = go.Figure()
#세부항목 지정
fig.add_trace(
go.Box(
y=df['A'], name='A'
)
)
fig.add_trace(
go.Box(
y=df['B'], name='B'
)
)
#그래프 보기
fig.show()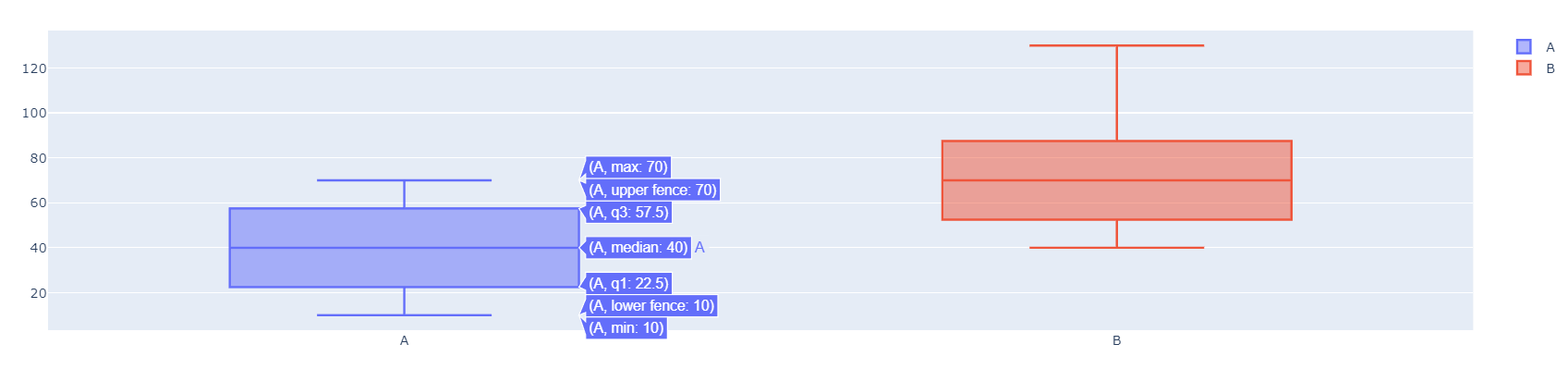
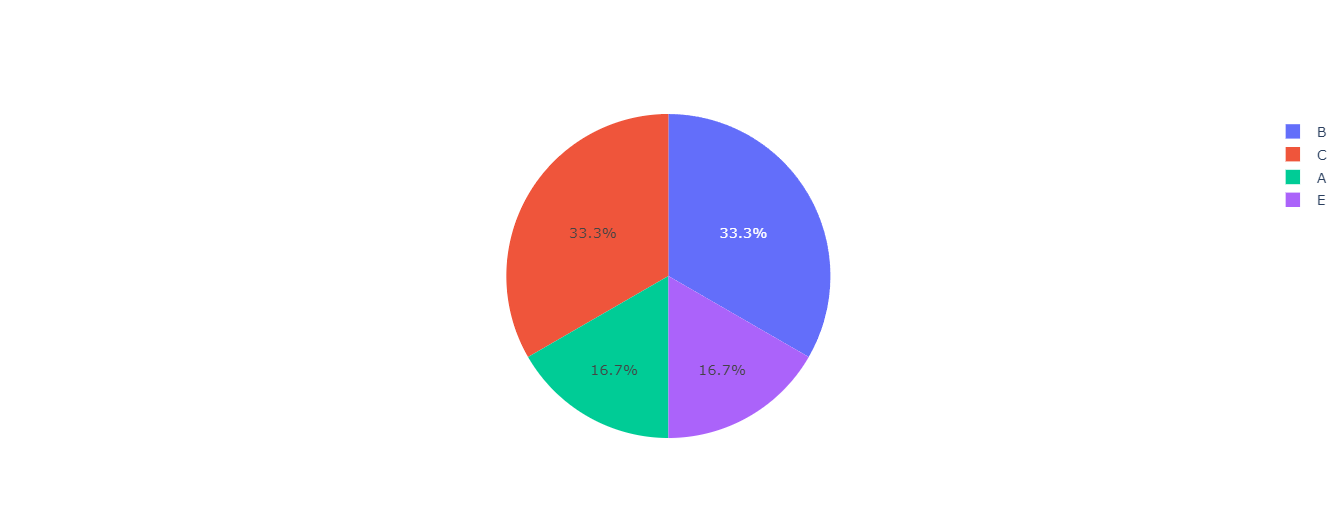
□ pie 그래프 시각화
○ 데이터프레임 생성 및 비중집계를 위해 groupby, count 사용
#데이터프레임 생성
data ={
'year':['2017','2017','2019','2020','2021','2021'],
'grade':['C','C','B','A','B','E']
}
df = pd.DataFrame(data)
#그룹바이 + 집계함수사용 : as_index=False 로 group한 기준 필드가 인덱스로 변환되는것을 방지
df1 = df.groupby('grade', as_index=False).count()
df2 = df.groupby('year', as_index=False).count()
○ 라이브러리 plotly.graph_objects 사용 : 시각화 그래프의 세부조정을 만들기 위해 사용
#객체판 생성
fig = go.Figure()
#세부항목 지정
fig.add_trace(
go.Pie(
labels=df1['grade'],values=df1['year'],name='A'
)
)
fig.add_trace(
go.Pie(
labels=df2['year'],values=df1['grade'],name='A'
)
)
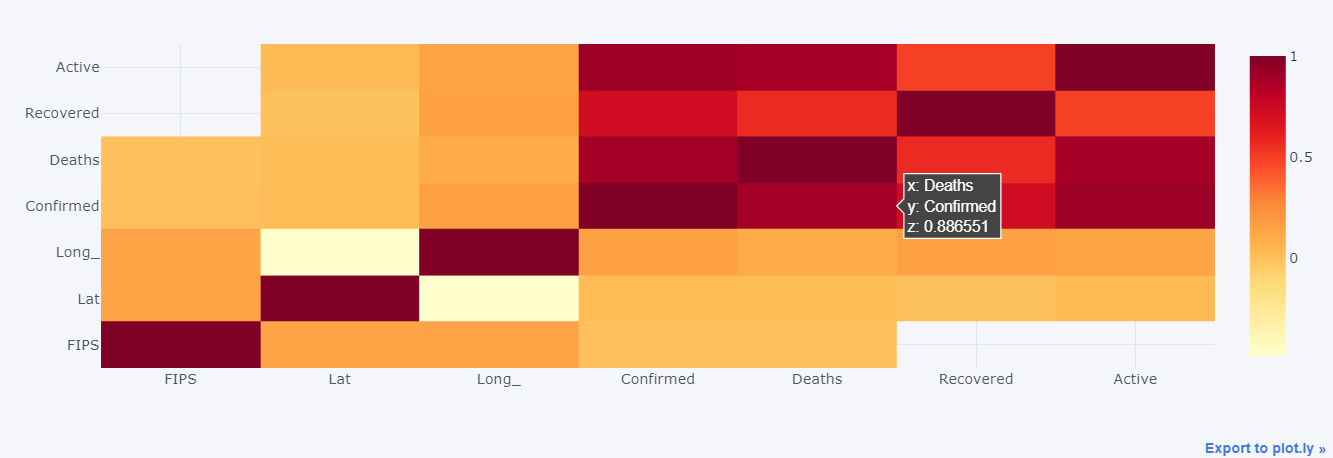
□ hitmap 그래프 시각화
○ Heatmap 그래프는 데이터의 상대적인 크기 또는 관계를 색상을 사용하여 시각적으로 표현하는 데 사용
○ 각각의 행과 열이 데이터의 카테고리를 나타내며, 각 셀의 색상이 해당 데이터의 크기 또는 관계를 나타냄
○ 데이터불러오기
doc = pd.read_csv("파일경로")
○ 상관관계 분석 + 히트맵 색상지정
- .corr() 상관관계 분석함수
- 텍스트 타입의 필드로 오류가 날 수 있어, 숫자타입 필드만을 대상으로 연산하고자 numeric_only=True 사용
- cf.colors.scales() 으로 색상 파레트 확인 후 지정
doc2 = doc.corr(numeric_only=True) #상관관계 .corr
cf.colors.scales() #색상표
doc2.iplot(kind='heatmap',colorscale='ylorrd')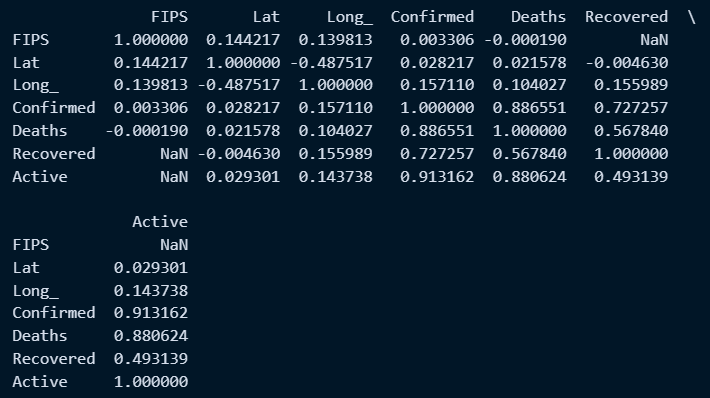

○ 라이브러리 plotly.graph_objects 사용 : 시각화 그래프의 세부조정을 만들기 위해 사용
#객체판 생성
fig = go.Figure()
#세부항목 지정
fig.add_trace(
go.Heatmap(
x=doc2.index,
y=doc2.columns,
z=doc2,
colorscale='puor'
)
)
□ Scatter 그래프 시각화
○ 점의 위치: 각 데이터 포인트는 좌표평면 상에 표시되어 해당 변수의 값을 나타냄
○ 점의 색상 또는 크기: 추가적인 정보를 나타내기 위해 점의 색상이나 크기를 활용할 수 있음 예를 들어, 세 번째 변수의 값을 색으로 표현하거나, 데이터의 중요도에 따라 크기를 조절할 수 있음
○ 상관관계 파악: 주로 두 변수 간의 상관관계를 시각적으로 파악하기 위해 사용. 두 변수 간의 양의 상관관계는 오른쪽 상단 방향으로, 음의 상관관계는 오른쪽 하단 방향으로 표시됨
○ 군집 파악: 데이터가 어떻게 군집되어 있는지 시각적으로 확인할 수 있음. 특히, 클러스터링 알고리즘의 결과를 시각화하는 데에도 사용
○ 라이브러리 plotly 사용 : 단순 시각화 그래프를 만들시
#데이터 불러오기
doc = pd.read_csv("파일경로")
#그래프 시각화
doc.iplot(kind='scatter', x='Recovered',y='Confirmed',mode='markers')
'Python > seaborn & matplotlib' 카테고리의 다른 글
| query, where 함수를 활용한 전처리 및 시각화 예제 (0) | 2024.02.16 |
|---|---|
| 전처리 후 시각화(Series 타입을 Seaborn으로 그래프화) (0) | 2024.02.16 |
| 판다스 parse_dates, assign 함수를 활용한 시각화 (0) | 2024.02.16 |
| Plotly ( + Bonus) (0) | 2024.02.15 |
| pie, barplot 차트 (+glob함수로 다중 데이터 불러오기) (0) | 2024.02.07 |



