□ 라이브러리 호출 및 한글 설정
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import glob
□ 다중 데이터 불러오기 및 불러오면서 데이터별 전처리(컬럼추가 및 값 넣기)
#파일 불러오기
child_data = glob.glob('C:/python/DataScience/Data/data/python_data/names/yob20*')
#불러온 파일을 저장할 빈 리스트 생성
child_list = list()
#반복문을 활용하여 데이터 집어 넣기
for i in child_data:
year = i.split('yob')[1].split('.')[0] #불러온 파일경로 및 파일명을 split하여 년도 추출
df = pd.read_csv(i, header=None)
df['year'] = year #불러온 파일별 year 컬럼 생성 및 split으로 추출한 year갑 저장
child_list.append(df)
child_concat = pd.concat(child_list) #데이터 병합
#데이터 컬럼명 지정
child_concat.columns = ['name', 'sex', 'counting', 'year']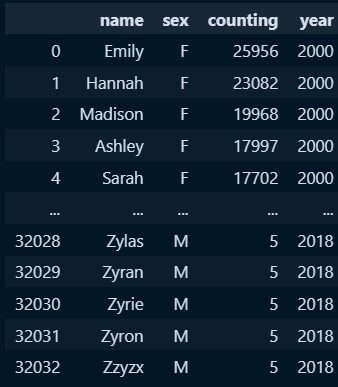
□ 집계함수를 사용하여 데이터 추출 : .groupby(필드명1).sum(필드명2)
sex_counts = child_concat.groupby('sex').sum('counting')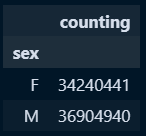
□ 파이형 차트 생성
# Figure 및 Subplot 생성
fig, ax = plt.subplots()
# 파이 그래프 그리기
ax.pie(sex_counts['counting'], labels=labels, autopct='%1.1f%%', colors=['skyblue', 'pink'], startangle=90)
# 그래프 제목 설정
ax.set_title('출생한 년도별 남녀수 합')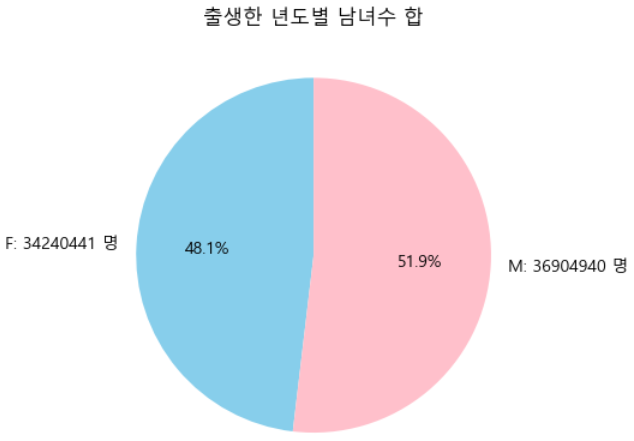
□ 그래프 객체 및 데이터지정을 통한 countplot 생성
○ hue 다변량 데이터를 그래프로 표현할 때는 색상으로 구분 설정
#라벨 지정
labels = [f'{sex_counts.index[0]}: {sex_counts.loc[sex_counts.index[0], "counting"]} 명',
f'{sex_counts.index[1]}: {sex_counts.loc[sex_counts.index[1], "counting"]} 명']
year_counts = child_concat.groupby(['year','sex']).count()
#틀생성
count, ax =plt.subplots()
plt.xticks(fontsize= 5) #x축열 폰트사이즈
#barplot 사용
sns.barplot(data=year_counts, x='year', y='counting',hue='sex', palette='viridis',ax=ax) #palette 막대그래프 색상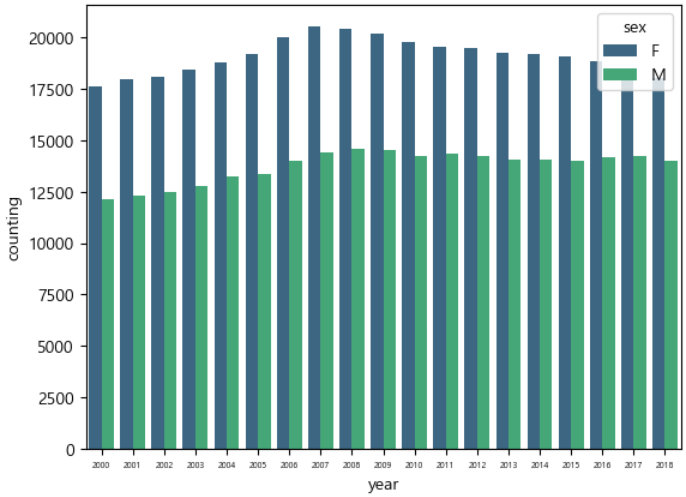
'Python > seaborn & matplotlib' 카테고리의 다른 글
| 판다스 parse_dates, assign 함수를 활용한 시각화 (0) | 2024.02.16 |
|---|---|
| Plotly ( + Bonus) (0) | 2024.02.15 |
| countplot 차트 (+glob함수로 다중 데이터 불러오기) (0) | 2024.02.07 |
| 파이형 그래프 (feat. 한글출력/폰트설정) (0) | 2024.02.06 |
| Seaborn 활용 데이터 시각화 (0) | 2024.02.06 |



