□ 라이브러리 호출 및 한글 설정
import glob
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
#한글폰트 사용 및 적용을 위한 코드
plt.rcParams['axes.unicode_minus'] = False
f_path = 'C:/Windows/Fonts/malgun.ttf'
font_name = font_manager.FontProperties(fname=f_path).get_name()
rc('font',family = font_name)
□ glob함수를 활용하여 다중 데이터 불러오기
#데이터 불러오기 glob함수 사용
data = glob.glob('C:/python/DataScience/Data/dust/*_*')
data_list = list() #불러온 데이터를 저장할 빈 리스트 생성
for i in data:
df = pd.read_csv(i, encoding='EUC-Kr') #불러올때 오류조치를 위해 encoding 방식 EUC-Kr 또는 cp949 사용
data_list.append(df) #리스트에 불러온 데이터 추가
dust_concat = pd.concat(data_list) #데이터 병합
□ 불필요한 컬럼 삭제
#전처리 : 불필요한 컬럼 드랍
dust_concat.drop(columns = ['Unnamed: 0'], inplace=True)
□ 데이터 재조합을 위한 melt 함수 사용 및 컬럼명 변경, 불필요 행 삭제
#데이터재조합 : melt 함수 사용
dust_concat_long = dust_concat.melt(id_vars='...1')
dust_concat_long.drop(columns=['variable'],inplace=True)
#컬럼명 변경
dust_concat_long = dust_concat_long.rename(columns={'...1': '지역명'})
#불필요한 행 삭제
dust_concat_long = dust_concat_long.drop(0)
#정렬 후 인덱스 초기화. reset_index()로 생성된 index 필드를 drop 시행
dust_concat_long=dust_concat_long.sort_values('지역명').reset_index().drop('index',axis=1)
□ 시각화 틀 생성
fig2,ax2=plt.subplots(figsize=(20,8))
□ 그래프 객체 및 데이터지정을 통한 countplot 생성
○ hue 다변량 데이터를 그래프로 표현할 때는 색상으로 구분 설정
sns.countplot(dust_concat_long,x='지역명',hue='value',ax=ax2)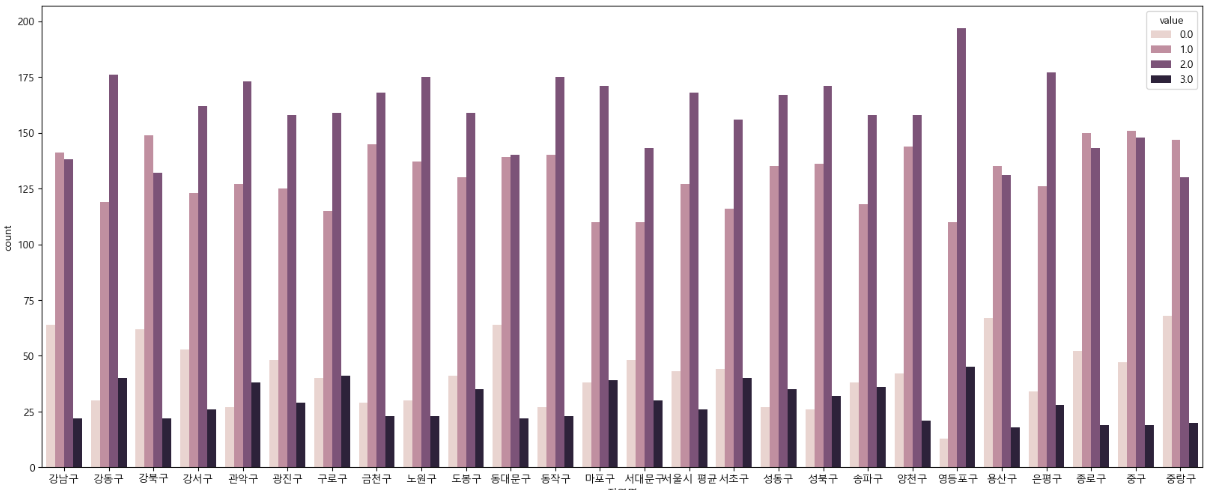
'Python > seaborn & matplotlib' 카테고리의 다른 글
| Plotly ( + Bonus) (0) | 2024.02.15 |
|---|---|
| pie, barplot 차트 (+glob함수로 다중 데이터 불러오기) (0) | 2024.02.07 |
| 파이형 그래프 (feat. 한글출력/폰트설정) (0) | 2024.02.06 |
| Seaborn 활용 데이터 시각화 (0) | 2024.02.06 |
| 다변량 그래프 (1) | 2024.02.06 |



