□ 개요
○ 데이터전처리
- Null 처리
- 불필요한 속성 제거
- 인코딩 수행
○ 모델학습 및 검증/예측/평가
- 결정트리, 랜덤포레스트, 로지스틱 획습 비교
- K 폴드 교차 검증
- Cross_val_score()와 GridSearchCV() 수행
□ 코드
○ 데이터 불러오기
#라이브러리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
#matplolib이 그래프를 노트북 셀 아래에 인라인으로 바로 표시됨
import seaborn as sns
#데이터 호출
titanic_df = pd.read_csv("./juData/train.csv")
titanic_df.head()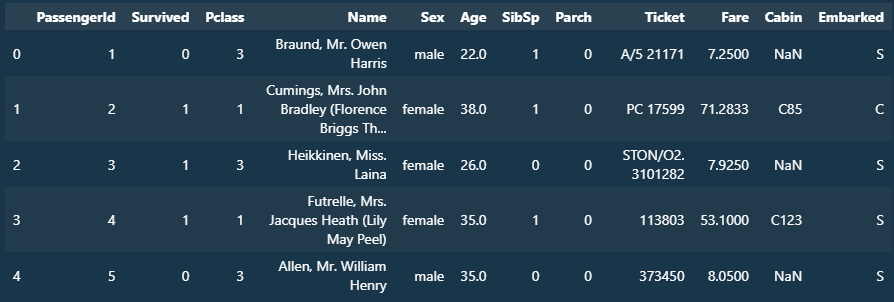
* 데이터 필드정보
- Passengerid: 탑승자 데이터 일련번호
- survived: 생존 여부, 0 = 사망, 1 = 생존
- Pclass: 티켓의 선실 등급, 1 = 일등석, 2 = 이등석, 3 = 삼등석
- sex: 탑승자 성별
- name: 탑승자 이름
- Age: 탑승자 나이
- sibsp: 같이 탑승한 형제자매 또는 배우자 인원수
- parch: 같이 탑승한 부모님 또는 어린이 인원수
- ticket: 티켓 번호
- fare: 요금
- cabin: 선실 번호
- embarked: 중간 정착 항구 C = Cherbourg, Q = Queenstown, S = Southampton
○ 데이터 EDA
titanic_df.info() #Age, Cabin, Embarked 필드를 보면 결측값이 있음
titanic_df.describe()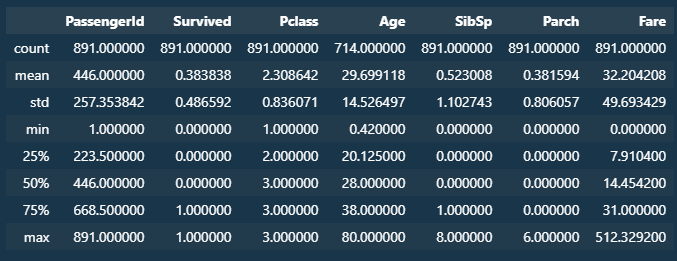
titanic_df.describe().transpose()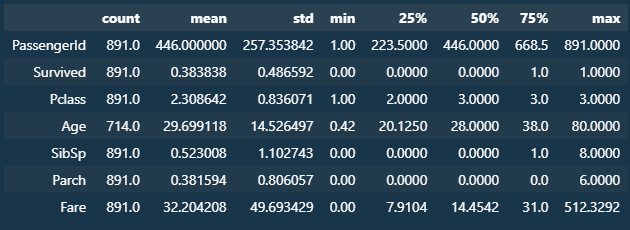
#NULL 값 처리 : AGE, Cabin, Embarked
titanic_df["Age"].fillna(titanic_df["Age"].mean(),inplace=True) #평균값으로 채움
titanic_df["Cabin"].fillna("N",inplace=True) #선실번호
titanic_df["Embarked"].fillna("N",inplace=True)
print(f"데이터 세트 Null 값 개수\n{titanic_df.isnull().sum()}")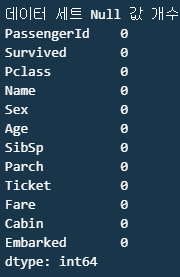
#주요컬럼 EDA
print(f"Sex값 분포\n{titanic_df['Sex'].value_counts()}")
print("\n")
print(f"Cabin값 분포\n{titanic_df['Cabin'].value_counts()}")
print("\n")
print(f"Embarked값 분포\n{titanic_df['Embarked'].value_counts()}")
print("\n")
#설별과 생존여부에서 생존여부를 기준으로 집계
titanic_df.groupby(["Sex","Survived"])["Survived"].count()
sns.barplot(x='Pclass', y='Survived', hue='Sex', data=titanic_df)
# 입력 age에 따라 구분값을 반환하는 함수 설정. DataFrame의 apply lambda식에 사용.
def get_category(age):
cat = ''
if age <= -1: cat = 'Unknown'
elif age <= 5: cat = 'Baby'
elif age <= 12: cat = 'Child'
elif age <= 18: cat = 'Teenager'
elif age <= 25: cat = 'Student'
elif age <= 35: cat = 'Young Adult'
elif age <= 60: cat = 'Adult'
else: cat = 'Elderly'
return cat
# 막대그래프의 크기 figure를 더 크게 설정
plt.figure(figsize=(10,6))
#X축의 값을 순차적으로 표시하기 위한 설정
group_names = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Elderly']
# lambda 식에 위에서 생성한 get_category( ) 함수를 반환값으로 지정.
# get_category(X)는 입력값으로 'Age' 컬럼값을 받아서 해당하는 cat 반환
titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x : get_category(x))
sns.barplot(x='Age_cat', y = 'Survived', hue='Sex', data=titanic_df, order=group_names)
#컬럼 삭제
titanic_df.drop('Age_cat', axis=1, inplace=True)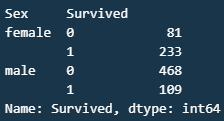


▶ 학습 전 전처리 및 데이터셋 트레이닝/타겟 데이터 분리
#레이블인코딩 : cabin, sex, embarked 숫자로 치환
from sklearn.preprocessing import LabelEncoder
def encode_features(dataDF):
features = ["Cabin","Sex","Embarked"]
le = LabelEncoder() #인코딩 객체 생성
#인코딩생성\
for feature in features:
le.fit(dataDF[feature]) #변환1
dataDF[feature] = le.transform(dataDF[feature]) #변환2
return dataDF
titanic_df = encode_features(titanic_df) #위에서 짠 함수는 데이터프레임을 인수로 받음
titanic_df.head()
#Null 처리 함수
def fillna(df):
df["Age"].fillna(df["Age"].mean(),inplace=True)
df["Cabin"].fillna("N", inplace=True)
df["Embarked"].fillna("N", inplace=True)
return df
#머신러닝 알고리즘관련 불필요 피처 제거
def drop_features(df):
df.drop(["PassengerId","Name","Ticket"], axis = 1, inplace = True)
return df
#레이블 인코딩
def format_features(df):
df["Cabin"] = df["Cabin"].str[:1]
features = ["Cabin", "Sex", "Embarked"]
for feature in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
#위에서 지정한 함수 한번에 묶은 함수정의
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return df
#데이터 재로딩 및 트레이닝, 테스트 셋 구축
titanic_df = pd.read_csv("./juData/train.csv")
y_titanic_df = titanic_df["Survived"]
X_titanic_df = titanic_df.drop("Survived",axis=1)
X_titanic_df = transform_features(X_titanic_df) #레이블 인코딩 함수를 지정한 것에 타이타닉 데이터 적재
#트레이닝, 테스트 셋 구축
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df, test_size=0.2, random_state=11)
print(f"트레이닝 데이터셋(feature)\n{X_train.shape}")
print("\n")
print(f"트레이닝 데이터셋(target)\n{y_train.shape}")
print("\n")
print(f"테스트 데이터셋(feature)\n{X_test.shape}")
print("\n")
print(f"테스트 데이터셋(target)\n{y_test.shape}")
▶ 모델 객체 생성 및 학습, 테스트
from sklearn.tree import DecisionTreeClassifier #의사결정나무 모델 라이브러리
from sklearn.ensemble import RandomForestClassifier #랜덤포레스트 > 앙상블 모델라이브러리
from sklearn.linear_model import LogisticRegression #선형회귀 라이브러리
from sklearn.metrics import accuracy_score #모델 정확도 측정관련 라이브러리
#결정트리, 랜덤포레스트, 로지스틱 회귀 모델 객체 생성
dt_clf = DecisionTreeClassifier(random_state=11)
rf_clf = RandomForestClassifier(random_state=11)
lr_clf = LogisticRegression(solver="liblinear")
#결정트리 학습, 예측, 평가
dt_clf.fit(X_train, y_train) #트레이닝 데이터 셋으로 학습
dt_pred = dt_clf.predict(X_test) #테스트 데이터 셋중 피아쳐 셋으로 예측
print(f"결정트리 정확도 : {accuracy_score(y_test,dt_pred)}") #예측정확도 출력 accuracy_score(테스트셋 타겟, 예측시도한 테스트셋 속성)
#랜덤 포레스트 학습, 예측, 평가
rf_clf.fit(X_train, y_train) #트레이닝 데이터 셋으로 학습
rf_pred = rf_clf.predict(X_test) #테스트 데이터 셋중 피아쳐 셋으로 예측
print(f"랜덤 포레스트 정확도 : {accuracy_score(y_test,rf_pred)}") #예측정확도 출력 accuracy_score(테스트셋 타겟, 예측시도한 테스트셋 속성)
#Logistic Regression 학습, 에측, 평가
lr_clf.fit(X_train,y_train) #트레이닝 데이터 셋으로 학습
lr_pred = lr_clf.predict(X_test) #테스트 데이터 셋중 피아쳐 셋으로 예측
print(f"Logistic Regression 정확도 : {accuracy_score(y_test, lr_pred)}") #예측정확도 출력 accuracy_score(테스트셋 타겟, 예측시도한 테스트셋 속성)


▶ 교차검증을 통한 모델생성 및 학습, 테스트
# 교차검증 1
#k-fold 함수
from sklearn.model_selection import KFold
# 폴드 세트가 5개인 kfold 객체생성, 폴드 수만큼 예측결과 저장을 위한 리스트 객체생성
def exec_kfold(clf, folds=5):
kfold = KFold(n_splits=folds) #폴드객체 생성
scores = list() #정확도 저장될 리스트
# Kfold 교차검증 수행
for iter_count, (train_index, test_index) in enumerate(kfold.split(X_titanic_df)):
# X_titanic_df 데이터에서 교차 검증별로 학습과 검증 데이터를 가리키는 index 생성
X_train, X_test = X_titanic_df.values[train_index], X_titanic_df.values[test_index]
y_train, y_test = y_titanic_df.values[train_index], y_titanic_df.values[test_index]
# Classifier 학습, 예측, 정확도 계산
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
scores.append(accuracy)
print(f"교차검증 : {iter_count}, {accuracy}")
# fold 5개의 평균 정확도 계산
mean_score = np.mean(scores)
print(f"평균 정확도 : {mean_score}")
#exe_kfold 호출 > 의사결정나무 지정
exec_kfold(dt_clf, folds=5)
# 교차검증 2 : cross_val_score
from sklearn.model_selection import cross_val_score
scores = cross_val_score(dt_clf, X_titanic_df, y_titanic_df, cv = 5) #cv k fold 5회 & 5개의 교차검증에대한 스코어가 저장됨
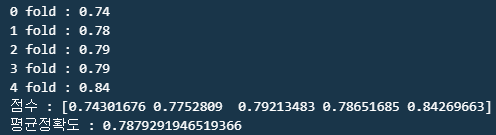
for iter_count, accuracy in enumerate(scores):
print(f"{iter_count} fold : {round(accuracy,2)}")
print(f"점수 : {scores}")
print(f"평균정확도 : {np.mean(scores)}")
# 교차검증 3 : GridSearchCV
from sklearn.model_selection import GridSearchCV
parameters = {"max_depth" : [2,3,5,10],
"min_samples_split" : [2,3,5],
"min_samples_leaf" : [1,5,8]}
grid_dclf = GridSearchCV(dt_clf, param_grid=parameters, scoring="accuracy", cv = 5) #의사결정나무 모델, 파라미터로 의사결정나무 모델 하이퍼파라미터 입력
grid_dclf.fit(X_train,y_train)
print('GridSearchCV 최적 하이퍼 파라미터 :', grid_dclf.best_params_)
print('GridSearchCV 최고 정확도: {0:.4f}'.format(grid_dclf.best_score_))
best_dclf = grid_dclf.best_estimator_
# GridSearchCV의 최적 하이퍼 파라미터로 학습된 Estimator로 예측 및 평가 수행.
dpredictions = best_dclf.predict(X_test)
accuracy = accuracy_score(y_test , dpredictions)
print('테스트 세트에서의 DecisionTreeClassifier 정확도 : {0:.4f}'.format(accuracy))

'Portfolio & Toy-Project' 카테고리의 다른 글
| 프로젝트 : 부산항만공사 서비스 제안관련 데이터분석-4 (0) | 2024.03.11 |
|---|---|
| 프로젝트 : 부산항만공사 서비스 제안관련 데이터분석-3 (0) | 2024.03.11 |
| 프로젝트 : 부산항만공사 서비스 제안관련 데이터분석-2 (0) | 2024.03.11 |
| 프로젝트 : 부산항만공사 서비스 제안관련 데이터분석-1 (0) | 2024.03.11 |
| 판다스 : .melt() 함수1 (0) | 2024.02.07 |



