https://dandora-90.tistory.com/298
Multiple Regression(다중회귀)
https://dandora-90.tistory.com/295 KNN_Regression&LinearRegression □ K 최근접 이웃 회귀(K-NN Regression) ○ K-최근접 이웃 회귀모델은 분류와 동일하게 가장먼저가까운 k개의 이웃을 찾음. ○ 그다음 이웃샘플의
dandora-90.tistory.com
위 글에 이어서..
학습점수를 높이기위해 속성을 엄청나게 늘리고 학습을 했더니 과대적합이 발생하였음. 무엇이 문제일까? 킹받는다...
아마 행 수 보다 속성 수가 많아, 과대적합이 발생된 것으로 예상되어, 조치가 필요하다고 생각됨.
과대적합을 해결하기위해 규제가 필요하다고 판단했고 규제를 위해 Ridge, Lasso 모델을 적용하기로함.
□ 릿지와 라쏘모델을 사용할 때 규제의 양을 임의로 조절할 수 있음
○ 이때 조절하는 요소를 하이퍼파라미터라고 부르는데, 우리는 alpha값이 크면 규제 강도가 세지므로 계수값을 더 줄이고 조금 더 과소 적합되도록 유도할 수 있음.
○ alpha 값이 작으면 계수를 줄이는 역할이 줄어들고 선형 회귀 모델과 유사해지므로 과대적합될 가능성이 커짐
○ Ridge
- 가중치가 많아지는 것을 Ridge로 규제함.
- 가중치^2(모델파라미터)를 규제하는 것을 L2 규제라고 부름.
○ Lasso
- 가중치의 절대값을 규제하는데 이를 L1 규제라고 부름.
- 계수의 크기를 아예 0으로 만들수 있음.
□규제 : 머신러닝 모델이 훈련세트를 너무 과도하게 학습하지 못하도록 훼방하는 것을 말함. 즉, 훈련세트에 과대적합이 되지 않도록 많는 것으로 선형 회귀모델의 경우 특성에 곱해지는 계수 또는 기울기의 크기를 작게 만든 작업임.
* 규제를 가하기전 평균과 표준편차를 직접 구해 특성을 표준점수로 바꾸어주는 데이터 스케일링 작업이 필요함. 이에 따라 StrandardScaler 클래스를 사용함.
○ 규제 적용전 전처리 → *규제를 가하기전 평균과 표준편차를 직접 구해 특성을 표준점수로 바꾸어주는 데이터 스케일링 작업이 필요함. 이에 따라 StrandardScaler 클래스를 사용함.
#규제 전에 표준화 필요 : 데이터 스케일링 (표준점수로 변환시키는 변환기)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_poly)
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)
print(f"스케일링 전 트레이닝 데이터\n{train_poly[:2]}")
print("\n")
print(f"스케일링 후 트레이닝 데이터\n{train_scaled[:2]}")
print("\n")
print(f"스케일링 전 테스트 데이터\n{test_poly[:2]}")
print("\n")
print(f"스케일링 후 테스트 데이터\n{test_scaled[:2]}")
○ Ridge 모델학습 : L2 규제 = 가중치^2(모델파라미터)를 규제하는 것을 L2 규제라고 부름
from sklearn.linear_model import Ridge
#릿지모델 생성
ridge = Ridge()
#학습
ridge.fit(train_scaled,train_target)
#트레이닝, 테스트 점수확인
print(f"트레이닝 데이터 학습점수 : {ridge.score(train_scaled,train_target)}")
print(f"테스트 데이터 학습점수 : {ridge.score(test_scaled,test_target)}")
※ 릿지와 라쏘모델을 사용할 때 규제의 양을 임의로 조절할 수 있음.
※ 이때 조절하는 요소를 하이퍼파라미터라고 부르는데, 우리는 alpha값이 크면 규제 강도가 세지므로 계수값을 더 줄이고 조금 더 과소 적합되도록 유도할 수 있음.
※ alpha 값이 작으면 계수를 줄이는 역할이 줄어들고 선형 회귀 모델과 유사해지므로 과대적합될 가능성이 커짐.
○ 최적의 파라미터 alpha 값 찾기
import matplotlib.pyplot as plt
train_score = list()
test_score = list()
alpha_list = [0.001, 0.01, 0.1, 1, 10 , 100] #6개의 alpha 값을 만들어 최적의 alpha 값을 찾음
for v in alpha_list:
ridge = Ridge(alpha=v) #릿지모델생성
ridge.fit(train_scaled,train_target) #트레이닝 세트 훈련
train_score.append(ridge.score(train_scaled, train_target))
test_score.append(ridge.score(test_scaled, test_target))
print(f"알파값\t:\t{v}")
print(f"트레이닝 점수\t:\t{ridge.score(train_scaled, train_target)}")
print(f"테스트 점수\t:\t{ridge.score(test_scaled, test_target)}")
print(f"트레이닝 - 테스트 점수\t:\t{ridge.score(train_scaled, train_target) - ridge.score(test_scaled, test_target)}")
print("\n")
○ 최적의 파라미터 alpha 값 찾기를 위한 시각화 진행
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel("alpha")
plt.ylabel("R^2")
plt.show()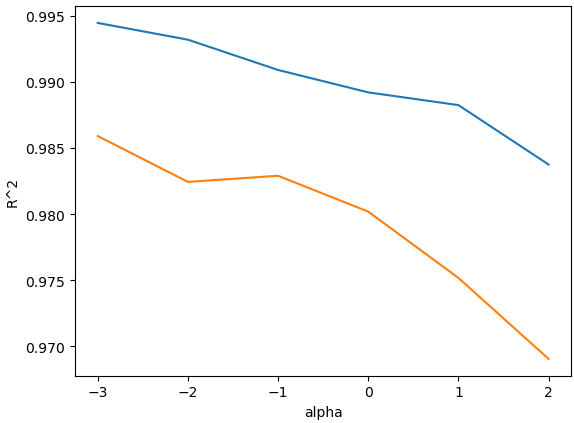
○ 최적의 알파값 적용을 통한 Ridge 모델 학습
ridge = Ridge(alpha=0.1)
ridge.fit(train_scaled, train_target)
print(f"트레이닝 점수\t:\t{ridge.score(train_scaled, train_target)}")
print(f"테스트 점수\t:\t{ridge.score(test_scaled, test_target)}")
○ Lasso 모델학습 : L1 규제 = 가중치의 절대값을 규제. 계수의 크기를 아예 0으로 만들수 있음
from sklearn.linear_model import Lasso #가중치의 절대값을 규제를 가함 L1규제
#모델생성
lasso = Lasso()
#학습
lasso.fit(train_scaled, train_target)
#트레이닝/테스트 학습점수
print(lasso.score(train_scaled, train_target))
print(lasso.score(test_scaled, test_target))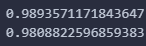
○ 최적의 파라미터 alpha 값 찾기
train_score = list()
test_score = list()
alpha_list = [0.001, 0.01, 0.1, 1, 10 , 100]
for v in alpha_list:
lasso = Lasso(alpha=v, max_iter=10000) #라쏘모델생성
lasso.fit(train_scaled,train_target) #트레이닝 세트 훈련
train_score.append(lasso.score(train_scaled, train_target))
test_score.append(lasso.score(test_scaled, test_target))
print(f"알파값\t:\t{v}")
print(f"트레이닝 점수\t:\t{lasso.score(train_scaled, train_target)}")
print(f"테스트 점수\t:\t{lasso.score(test_scaled, test_target)}")
print(f"트레이닝 - 테스트 점수\t:\t{lasso.score(train_scaled, train_target) - lasso.score(test_scaled, test_target)}")
print("\n")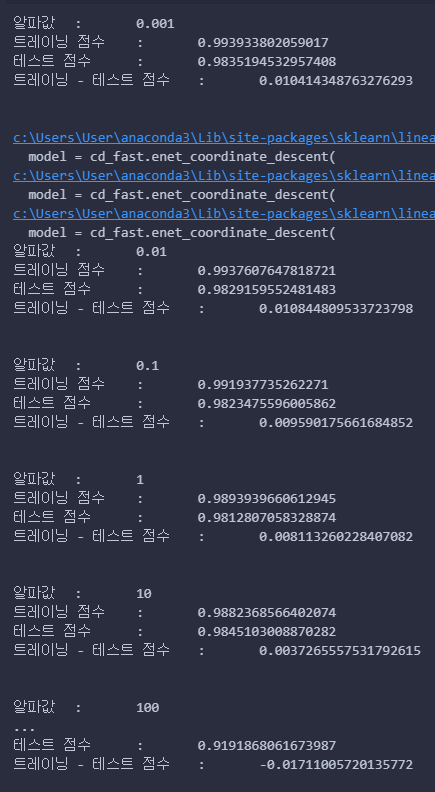
○ 최적의 파라미터 alpha 값 찾기를 위한 시각화 진행
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel("alpha")
plt.ylabel("R^2")
plt.show()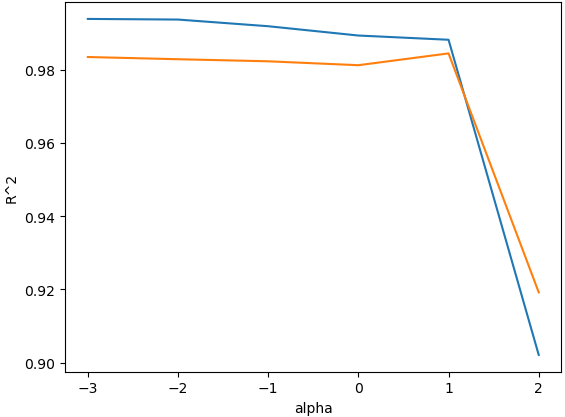
○ 최적의 알파값 적용을 통한 Lasso 모델 학습
#라쏘 모델생성
lasso = Lasso(alpha=10)
#라쏘 학습
lasso.fit(train_scaled,train_target)
print(f"트레이닝 점수\t:\t{lasso.score(train_scaled, train_target)}")
print(f"테스트 점수\t:\t{lasso.score(test_scaled, test_target)}")
※ 다중 속성을 생성후 선형다중회귀를 통한 학습시 과대/과소적합이 발생한다면 Ridge를 활용해 L2규제, 즉 가중치^2에 규제를 가하거나 Lasso를 활용해 L1 규제, 즉 가중치의 절대값을 규제하여 학습점수를 높일 수 있음!!추가로 Lasso를 활용해 계수의 크기를 아예 0으로 만들수 있음.
+ TMI) Lasso는 계수를 0으로 만들기
#계수 값을 아예 0으로 만들기
print(np.sum(lasso.coef_ == 0))
'Python > 머신러닝+딥러닝 Ⅰ' 카테고리의 다른 글
| 확률적경사하강법 (1) | 2024.03.22 |
|---|---|
| Logistic_KNN (0) | 2024.03.22 |
| Multiple Regression(다중회귀) (0) | 2024.03.15 |
| KNN_Regression&LinearRegression (1) | 2024.03.13 |
| K-Nearest Neighbor : K-NN 알고리즘 (3) | 2024.03.12 |



