□ 내용
○ 쿠팡에서 특정 키워드에 따른 검색결과 상품 들 중 로켓배송이 되는 품목만 크롤링
○ 특이사항
- 변수명 = .select('li[class=search-product') → li 태그 중 클래스명이 정확히 search-product 인 것을 앞 코드와 같이 표현
▶ .select('li.search-product')과 같이 쓰면 아래 이미지와 같이 특정 클래스명이 들어간것을 모두 파악하여 처리해야할 변수 및 정확도가 떨어짐
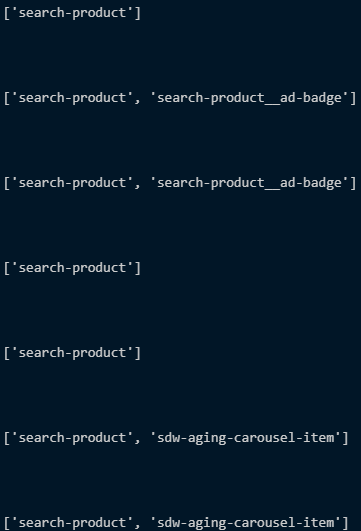
- continue 문 : 조건이 True이면 아래 코드까지 진행, 조건이 False면 위로 올라가서 코드실행
#로켓뱃지
rocket_pd = i.select_one('.badge.rocket')
if rocket_pd:
continue #로켓벳지가 없다면 위로 올라가서 코드 실행. 있다면 아래 코드 실행
- .get() 함수 : BeautifulSoup에서 특정 속성의 값을 가져오는 데 사용되는데 주로 HTML 태그 안에서 속성의 값을 추출하는 데 활용함
▶ .get('data-img-src') 은 data-img-src 속성의 값을 가져오겠다는 의미
- 이미지 저장 : wb 활용 (바이너리형식으로 저장)
□ 코드
#라이브러리 호출
import requests
from bs4 import BeautifulSoup
#크롤링 페이지 : 입력받은 값이 url 상의 q 파라메터로 적용
pd_word = input('검색품목을 입력해주세요.\t:\t')
url = 'https://www.coupang.com/np/search?component=&q='
pd_url = url + pd_word
representative_url = 'https://www.coupang.com'
#requests setting : timeout 특정 시간을 주고 대기. 해당 시간까지 진행이 안되면 오류 반환
get_information = requests.get(pd_url, timeout = 5) #크롤링 대상사이트에 요청
all_data = get_information.text #요청하여 받은(get) 데이터 텍스트로 저장
parser = BeautifulSoup(all_data, 'html.parser') #텍스트로 저장된 데이터를 html.parser를 파싱세팅
#타겟 상세영역 구분
#li태크에 class속성이 search-product 인것
item_area = parser.select('li[class=search-product ]')
for index, i in enumerate(item_area):
index +=1
#로켓뱃지
rocket_pd = i.select_one('.badge.rocket')
if rocket_pd:
continue #로켓벳지가 없다면 위로 올라가서 코드 실행. 있다면 아래 코드 실행
#제품명 : 클래스명이 search-product인 li 태그 하위 태그 중 클래스명 name 을 가진 요소
pd_nm = i.select_one('.name ').string
#가격 : 클래스명이 search-product인 li 태그 하위 태그 중 클래스명 sale 을 가진 요소. 앞뒤 공백제거를 위해 .strip 사용
pd_pc = i.select_one('.sale ').text.strip()
#썸네일 : 클래스명이 search-product인 li 태그 하위 태그 중 클래스명이 search-product-wrap-img 인 img 태그인 요소
pd_thumb_small = str(i.select_one('img.search-product-wrap-img').get('data-img-src'))
if pd_thumb_small == None:
pd_thumb_small = 'http:' + i.select_one('img.search-product-wrap-img')['src']
elif pd_thumb_small != None:
pd_thumb_small = 'http:' + str(i.select_one('img.search-product-wrap-img').get('data-img-src')) #.get() 메서드는 BeautifulSoup에서 특정 속성의 값을 가져오는 데 사용됩니다. 주로 HTML 태그 안에서 속성의 값을 추출하는 데 활용
#링크 : 클래스명이 search-product인 li 태그 하위 태그 중 a태그의 href 속성 값 가져오기
pd_link = representative_url+ i.select_one('a')['href']
#이미지 다운 : wb 바이너리파일 저장
try:
img_dwn = requests.get(pd_thumb_small)
with open(f'쿠팡 {pd_word} {index}위 상품.jpg','wb') as f:
f.write(img_dwn.content)
except:
pass
print(f'\n□\t{index}위 제품\n(1)제품명\t:\t{pd_nm}\n(2)가격\t:\t{pd_pc}\n(3)썸네일\t:\t{pd_thumb_small}\n(4)링크\t:\t{pd_link}')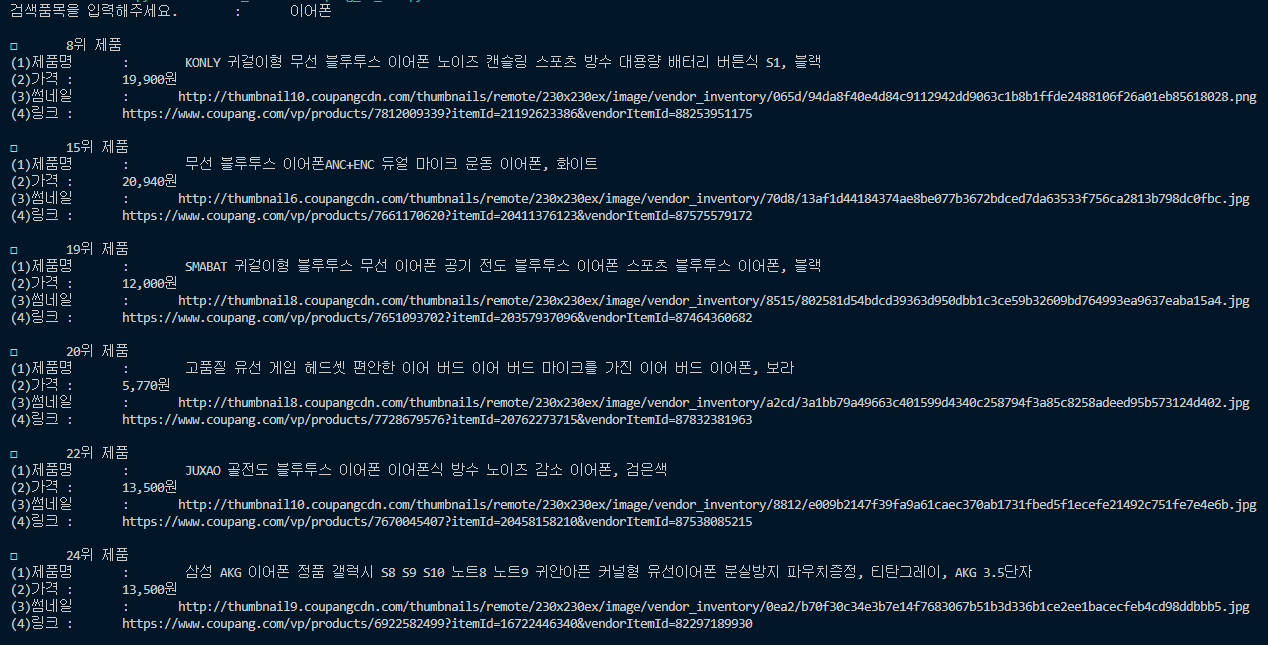
'Python > Python_Crawling' 카테고리의 다른 글
| Selenium 개요 (0) | 2024.02.14 |
|---|---|
| 특정 사이트 크롤링 및 데이터프레임 생성 (0) | 2024.02.13 |
| CGV 무비차트 크롤링 (1) | 2024.02.11 |
| SSG 이벤트 크롤링 : select, find_all(string=True) (1) | 2024.02.09 |
| 다음 뉴스(제목, 링크, 회사, 카테고리) 크롤링 (1) | 2024.02.05 |



