□ 공공데이터 : https://www.data.go.kr/
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
□ 사전작업(회원가입 완료되었다고 가정)
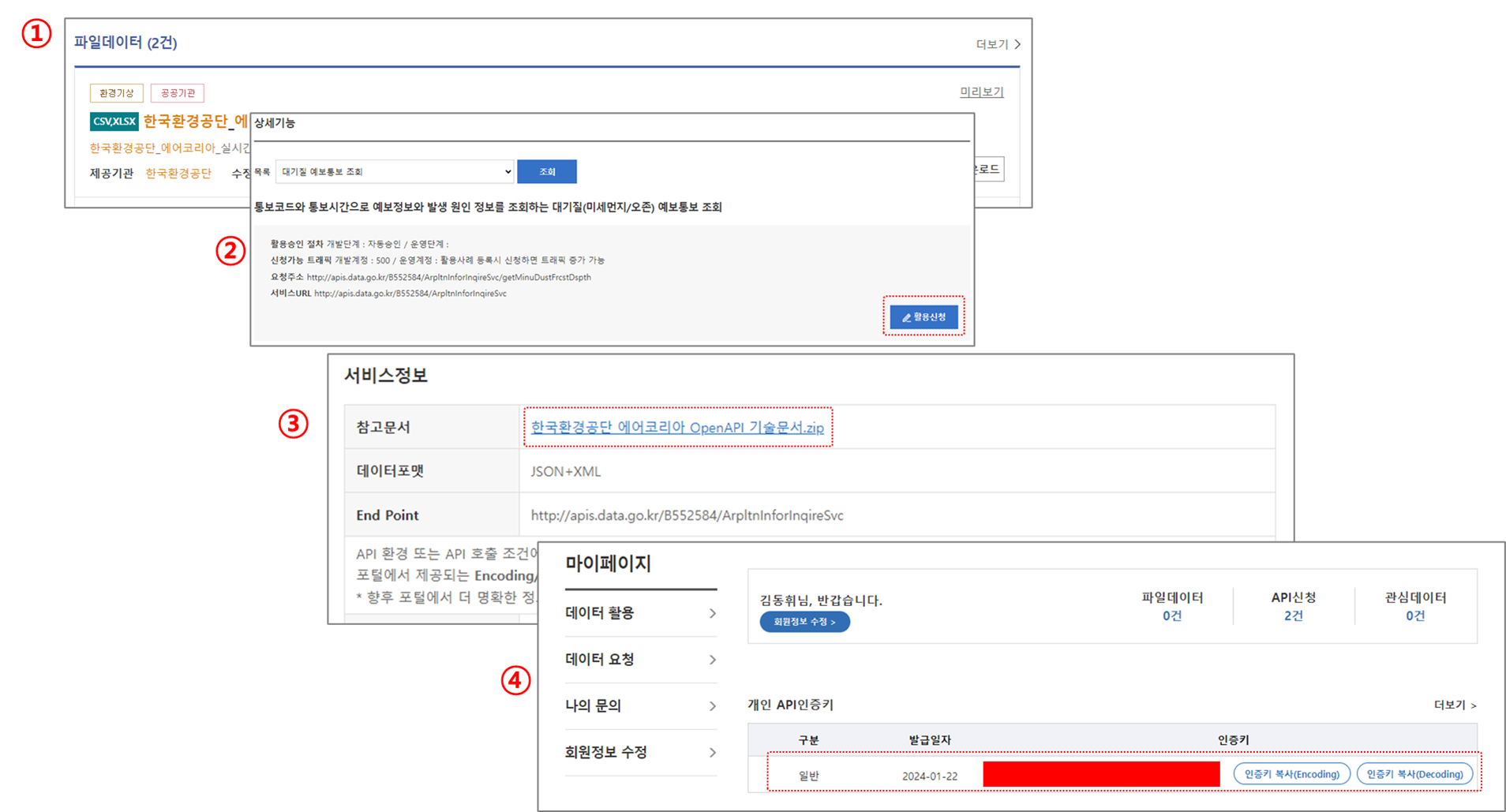
① API 신청하고자할 데이터 조회/검색
② 해당 데이터 상세보기 > 활용신청 클릭
③ 신청승인이되면 요청한 데이터의 기술목록 다운 및 API 링크, 변수 등 파악
④ 개인 인증키 파악
□ 사전작업 완료 후 postman에서 API링크와 인증키 입력 후 데이터 요청/수신 여부 확인
○ 링크 및 인증키, 변수등을 잘 입력했다면 아래와 같이 수신된 데이터가 표시됨
* 작성자는 xml 형식의 데이터를 요청 및 수신받은 상황임


| □ XML(Extensible Markup Language) ○ 특정 목적에 따라 데이터를 태그로 감싸서 마크업하는 범용적인 포맷 ○ 마크업 언어는 태그등을 이용하여 데이터의 구조를 기술하는 언어의 한 가지 ○ 가장 친숙한 마크업 언어가 HTML ○ XML은 HTML과 마찬가지로 데이터를 계층 구조로 표현 ○ XML기본구조 : <태그 속성 = '속성값>내용<태그> - 태그와 속성은 특정 목적에 따라 임의로 이름을 정해서 사용 |
□ Postman에서 데이터가 잘 수신되는지 확인했다면 이젠 Python으로 코딩 진행
○ 활용 라이브러리
#라이브러리 호출
import requests #API서버로 데이터 요청 및 수신을 받기 위해 호출
from bs4 import BeautifulSoup #xml 마크업언어 파싱을 위해 호출
○ 세부 코딩내용
#라이브러리 호출
import requests #API서버로 데이터 요청 및 수신을 받기 위해 호출
from bs4 import BeautifulSoup #xml 마크업언어 파싱을 위해 호출
#개인인증키
self_key = '인증키'
#제공변수
params ='&numOfRows=100&pageNo=1&sidoName=%EC%84%9C%EC%9A%B8&ver=1.0'
#api주소
open_api = 'https://apis.data.go.kr/B552584/ArpltnInforInqireSvc/getCtprvnRltmMesureDnsty?serviceKey=' + self_key + params
#설정한 주소로부터 데이터 요청 및 수신
core_res = requests.get(open_api)
print(f'□■□■□■□■□■ 요청 및 결과\t:\t{core_res}')
parser_soup = BeautifulSoup(core_res.content,'html.parser') #BeautifulSoup을 활용하여 수신받은 데이터 html 파싱
items_data = parser_soup.find_all('item') #모든 item별 태그안의 데이터 추출
for v in items_data:
sido_Name = v.find('sidoname') #item 태그 안에 있는 sidoname 태그의 값 추출
station_Name = v.find('stationname') #item 태그 안에 있는 stationname 태그의 값 추출
print(f'{sido_Name.get_text()} : {station_Name.get_text()}')
print('□■□■□■□■□■ 출력완료')'Python > Python_Crawling' 카테고리의 다른 글
| 네이버 뷰 크롤링 : 제목, 작성자, 링크 + 예외처리 (1) | 2024.01.30 |
|---|---|
| 특정 영역의 하위태그별 데이터 크롤링 (0) | 2024.01.28 |
| 네이버 API : 데이터 엑셀저장 (0) | 2024.01.21 |
| 네이버 API : 파이썬 코딩 (1) | 2024.01.21 |
| API/JSON 이란?(+postman 활용 데이터 get) (0) | 2024.01.19 |



