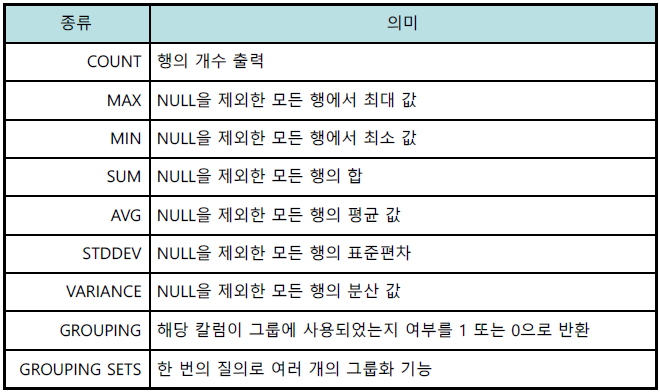
□ 그룹함수
○ 테이블의 전체 행을 하나 이상의 컬럼을 기준으로 그룹화하여 그룹별로 결과를 출력하는 함수
○ 그룹함수는 통계적인 결과를 출력하는데 자주 사용

○ GROUP BY : 전체 행을 group_by_expression을 기준으로 그룹화
○ HAVING : GROUP BY 절에 의해 생성된 그룹별로 조건 부여
○ 종류
□ Count함수
○ 테이블에서 조건을 만족하는 행의 갯수를 반환하는 함수 COUNT ({* | [DISTINCT | ALL] expr})
○ ‘*’은 NULL을 포함한 모든 행의 개수
○ DISTINCT는 중복되는 값을 제외한 행의 개수
○ ALL은 중복되는 값을 포함한 행의 개수, 기본값은 ALL
○ expr 인수에서 사용 가능한 데이터 타입은 CHAR, VARCHAR2,
○ NUMBER, DATE 타입
select count(comm) from professor
where deptno = 101;
□ AVG, SUM함수
○ AVG ([DISTINCT | ALL] expr)
○ SUM ([DISTINCT | ALL] expr)
select avg(weight), sum(weight) from student
where deptno = 101;
□ MIN, MAX 함수
select max(weight), min(height) from student
where deptno = 102;
□ STDDEV(표준편차), VARIANCE(분산) 함수
select stddev(sal), variance(sal)
from professor;
□ Group by 절
○ 특정 칼럼 값을 기준으로 테이블의 전체 행을 그룹별로 나누기 위한 절
○ 예를 들어, 교수 테이블에서 소속 학과별이나 직급별로 평균 급여를 구하는 경우
○ GROUP BY 절에 명시되지 않은 칼럼은 그룹함수와 함께 사용할 수 없음
○ 규칙
- 그룹핑 전에 WHERE 절을 사용하여 그룹 대상 집합을 먼저 선택
- GROUP BY 절에는 반드시 칼럼 이름을 포함해야 하며 칼럼 별명은 사용할 수 없음
- 그룹별 출력 순서는 오름차순으로 정렬
- SELECT 절에서 나열된 칼럼 이름이나 표현식은 GROUP BY 절에서 반드시 명시
- GROUP BY절에서 명시한 컬럼 이름은 SELECT절에서 명시하지 않아도된다
□다중 컬럼을 이용한 그룹핑
○ 하나 이상의 칼럼을 사용하여 그룹을 나누고, 그룹별로 다시 서브 그룹을 나눔
○ 전체 교수를 학과별로 먼저 그룹핑한 다음, 학과별 교수를 직급별로 다시 그룹핑하는 경우
select deptno, avg(sal), min(sal), max(sal)
from professor
group by deptno;
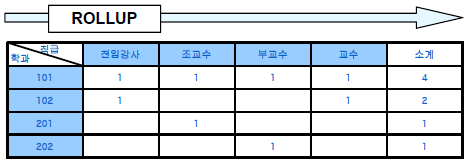
□ ROLLUP, CUBE 연산자
○ ROLLUP
- GROUP BY 절의 그룹 조건에 따라 전체 행을 그룹화하고 각 그룹에 대해 부분합을 구하는 연산자
- GROUP BY 절에 칼럼의 수가 n개이면 ROLLUP 그룹핑 조합은 n+1개
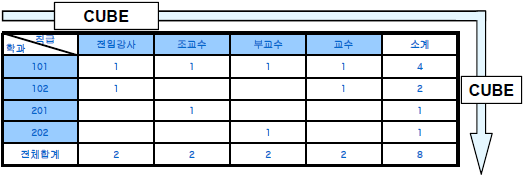
○ CUBE
- ROLLUP에 의한 그룹 결과와 GROUP BY 절에 기술된 조건에 따라 그룹 조합을 만드는 연산자
- GROUP BY 절에 칼럼의 수가 n개이면 CUBE 그룹핑 조합은 2n개
○ SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY [ROLLUP | CUBE] group_by_expression]
[HAVING group_condition]
-ROLLUP
select deptno, sum(sal)
from professor
group by rollup(deptno)
-ROLLUP
select deptno, position, count(*)
from professor
group by rollup(deptno, position);
-CUBE
select deptno, position, count(*)
from professor group by cube(deptno, position);
□ GROUPING 함수
○ 인수로 지정된 칼럼이 ROLLUP이나 CUBE 연산자로 생성된 그룹조합에서 사용되었는지 여부를 1 또는 0으로 반환
○ 사용하면 0, 아니면 1
○ SELECT column, group_function(column), GROUPING(column)
FROM table
[WHERE condition]
[GROUP BY [ROLLUP | CUBE] group_by_expression]
[HAVING group_condition]
select deptno, grade, count(*), grouping(deptno), grouping(grade) from student
group by rollup(deptno, grade);
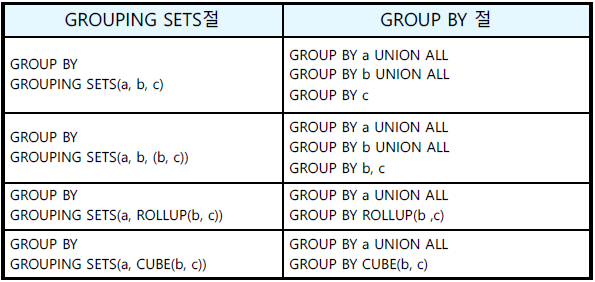
□ GROUPING SETS 함수
○ GROUP BY 절에서 그룹 조건을 여러 개 지정할 수 있는 함수
○ 각 그룹 조건에 대해 별도로 GROUP BY한 결과를 UNION ALL한결과와 동일
○ SELECT column, group_function(column), GROUPING(column)
FROM table
[WHERE condition]
[GROUP BY [ROLLUP | CUBE] group_by_expression]
[GROUPING SETS(column, column…), …]
[HAVING group_condition]
select deptno, grade, to_char(birthdate, 'YYYY'), count(*) from student
group by grouping sets((deptno, grade), (deptno, to_char(birthdate, 'YYYY')));
□ HAVING 절
○ GROUP BY 절에 의해 생성된 그룹을 대상으로 조건을 적용
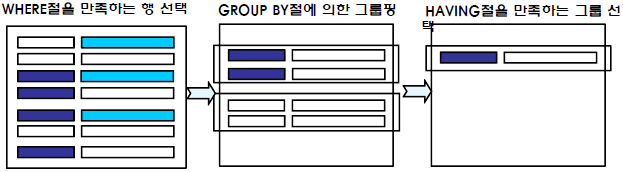
○ HAVING 절의 실행 과정
- 테이블에서 WHERE 절에 의해 조건을 만족하는 행 집합을 선택
- 행 집합을 GROUP BY 절에 의해 그룹핑
- HAVING 절에 의해 조건을 만족하는 그룹을 선택
○ SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column]
select grade, count(*), round(avg(height)) avg_height, round(avg(weight)) avg_weight
from student group by grade
order by avg_height desc
□ HAVING 절과 WHERE 절의 성능차이
○ HAVING 절
- 내부 정렬 과정에 의해 그룹화된 결과 집합에 대해 검색 조건 실행
○ WHERE 절
- 그룹화하기 전에 먼저 검색 조건 실행
○ 실무 데이터베이스 관점
- WHERE 절의 검색 조건을 먼저 실행하는 방법이 효율적
○ 그룹화하는 행 집합을 줄여서 내부 정렬 시간을 단축
○ SQL 처리 성능 향상
'DB > SQL_Example' 카테고리의 다른 글
| 서브쿼리 (By Oracle) (0) | 2024.01.22 |
|---|---|
| 조인함수 (By Oracle) (0) | 2024.01.22 |
| 일반함수 (by Oracle) (0) | 2024.01.19 |
| 데이터 타입변환 (by Oracle) (0) | 2024.01.19 |
| 문자함수 / 숫자함수 / 날짜함수(by Oracle) (0) | 2024.01.19 |



